

Workshop – Produce Like a Nerd (1): Oh Gott, das ist doch eine Kommandozeile…
Die Geschichte begann mit einer Wette vor 17 Jahren, also in einer Zeit ohne iPhones oder sogar Tablets. Ich hatte gerade ein neues Apple Video-iPod angeschleppt und ein paar Kumpels in der Arbeit — ebenso wie ich mit Bandhintergrund — meinten, es wäre doch super, wenn man das irgendwie zum Musikmachen verwenden könnte. Ob man nicht ein Programm für das Ding schreiben könnte, mit dem man seine eigenen Noten anzeigen und gleichzeitig irgendwie ein Backingtrack dazu abspielen kann? Das geht bestimmt nicht…
Naja, irgendetwas programmieren wäre schon möglich gewesen, aber der ganze Aufwand auf einer ziemlich exotischen Hardwareplattform nur wegen einer Wette? Andererseits könnte ein Video-iPod doch auch — naheliegende Idee 😉 — ein Video abspielen, also eines, das die Noten anzeigt, und der Backingtrack wäre dann einfach eine Audiospur im Video. Da ich sowieso schon damals diverse passende Open-Source-Tools verwendet hatte — wie beispielsweise lilypond für Notensatz von Bandarrangements und ffmpeg für Videobearbeitung — könnte ich damit händisch eine simple Werkzeugkette bauen. Und so entstand aus einer einfachen Textdatei und praktisch ohne manuellen Eingriff ein Notenvideo mit Audiospur. Bach BWV 639.
Strike. Ich hatte die Wette damals gewonnen (siehe Bild 1). Und sie hat fundamental die Art verändert, wie ich seither Arrangements produziere.

Okay, genug der Vorrede. Worum geht es in diesem Artikel?
Ich zeige einen Ansatz, wie man mit kostenlosen Open-Source-Tools für einen Song aus Textdateien mit Musik- und Konfigurationsdaten folgendes weitgehend automatisch erzeugen kann:
- eine PDF-Partitur und diverse PDF-Stimmauszüge,
- eine passende MIDI-Datei mit allen Stimmen (und etwas darauf angewandter Humanisierung),
- Instrumentaudiodateien mit diversen konfigurierbaren Audioeffekten, und
- Videodateien für diverse Ausgabegeräte, die einen Stimmauszug anzeigen und mehrere unterschiedliche Mischungen der Audiospuren als wählbare Audiobackingtracks enthalten
Und man kann diese Dateien auf jeder beliebigen Plattform erzeugen lassen, auf der man diese Open-Source-Tools installieren kann, also auf Windows, Linux, MacOS oder anderen.
Wozu soll denn so etwas gut sein? Sehr einfach: ich trete mit unterschiedlichen kleinen Besetzungen live auf: mal als Duo mit meiner Frau oder als Trio mit Kumpels. Dann können wir Arrangementvideos auf einem Tablet auf der Bühne abspielen und nach Bedarf Backingtracks auswählen mit genau den Stimmen, die gerade nicht live gespielt werden. Das Ganze geht als Stereospur in das Live-Mischpult und wird synchron zu den Noten im Video abgespielt. Die Noten im Video werden so auch rechtzeitig umgeblättert…
Es gibt aber einen Haken — und vermutlich werden spätestens jetzt viele aufhören zu lesen —: für einen Song erstellt man eine Textdatei für das Arrangement (in einer Standardnotation des Notensatzprogramms Lilypond) und eine Konfigurationstextdatei für die Beschreibung der Instrumentaudiospuren, der Audioeffekte und der Videoeigenschaften sowie der diversen Spuren in den Videos.
Per KOMMANDOZEILE werden diverse Open-Source-Programme aufgerufen, die die eigentliche Arbeit erledigen. Aber diese Werkzeugkette wird von einem einzigen Programm koordiniert, dem LilypondToBandVideoConverter (abgekürzt “ltbvc”). Er steuert die Verarbeitungsschritte: basierend auf Informationen in einer song-abhängigen Konfigurationsdatei plus der Arrangementdatei mit den Noten der Stimmen, fügt das Programm Zusatzinformation hinzu, humanisiert MIDI-Stimmen und ruft dazu auch die nötigen externen Tools korrekt parametriert auf.
Dieser Prozess ist vollautomatisch: wenn die Konfigurations- und Lilyponddatei vollständig vorliegen, läuft die Verarbeitung ohne manuellen Eingriff durch und kann natürlich auch beliebig oft wiederholt und auch schnell angepasst werden.
So ganz neben der Spur ist dieses Vorgehen nicht, weil beispielsweise Leute mit eingeschränkter Sehfähigkeit oft viel besser rein textbasiert arbeiten können. Das ist jetzt für mich nicht anwendbar; trotzdem mag ich den Ansatz. Wir werden aber in Teil 2 sehen, dass man einige Teile des Prozesses auch durch eine (WYSIWYG-)DAW massiv unterstützen kann, aber wir schauen uns jetzt erst einmal den DAW-losen Prozess an.
Verwendete Open Source Programme
Damit das alles funktioniert, muss man sich einige Programme installieren, die aber alle unter Windows, MacOS und Linux laufen, weil es eben Kommandozeilenprogramme sind:
- python3: ein Interpreter für eine gängige Skriptsprache (er ist bei vielen Betriebssystemen sowieso schon vorinstalliert),
- lilypond: ein textbasiertes Notensatzprogramm [Lilypond] für die Partitur, die Stimmauszüge, die Rohmididatei und für die Bilder der Seiten, die dann in den Videos verwendet werden,
- ffmpeg: ein Programm für Videogenerierung und -bearbeitung [FFMpeg],
- fluidsynth: ein Konverter von MIDI auf Audio über Soundfonts [Fluidsynth], und
- sox: ein Programm für Audioeffekte [SoX].
Für Fluidsynth braucht man noch einen guten Soundfont; es gibt viele davon im Internet, der gängigste ist beispielsweise FluidR3_GM.sf2 [SFNT-Fluid].
Es gibt darüber hinaus keine Anforderungen an die Programmversionen, da eher deren Standardfunktionen genutzt werden: meist funktioniert eine bereits vorhandene Version der obigen Programme.
Und dann kann man sich kostenlos und natürlich als Open-Source den LilypondToBandVideoConverter von GitHub oder PyPi herunterladen [LTBVC] und installieren und ist dann startklar.
Zumindest wenn man in der Lage ist, auf seiner Plattform ein Konsolfenster zu öffnen…
Bearbeitungsphasen
Das Programm hat nach seinen Ergebnistypen benannte Bearbeitungsphasen (die auf Englisch sind und auch auf der Kommandozeile so heißen):
- extract: erzeugt Stimmauszüge für einzelne Instrumente,
- score: erzeugt die komplette Partitur mit allen Stimmen,
- midi: erzeugt eine (etwas humanisierte) MIDI-Datei mit allen Stimmen und konfigurierbaren MIDI-Instrumenten, Pan-Positionen und Lautstärken,
- silentvideo: erzeugt ein oder mehrere stumme Videos, die Stimmauszüge oder die Partitur gemäß der Songgeschwindigkeit darstellen, korrekt umblättern und als Hilfe auch die jeweils aktuelle Taktnummer als Untertitel anzeigen,
- rawaudio: erzeugt rohe Audiodateien für alle Instrumentstimmen aus der MIDI-Datei,
- refinedaudio: wendet konfigurierbare Effektketten auf die rohen Audiodateien an und erzeugt verfeinerte Audiodateien,
- mix: mischt die verfeinerten Audiodateien zu Submixes zusammen mit konfigurierbarer Gruppierung und Pan- und Lautstärkeeinstellungen und etwaigen Masteringeffekten, und
- finalvideo: kombiniert die Submixes und die stummen Videos zu finalen Videodateien mit wählbaren Audiospuren
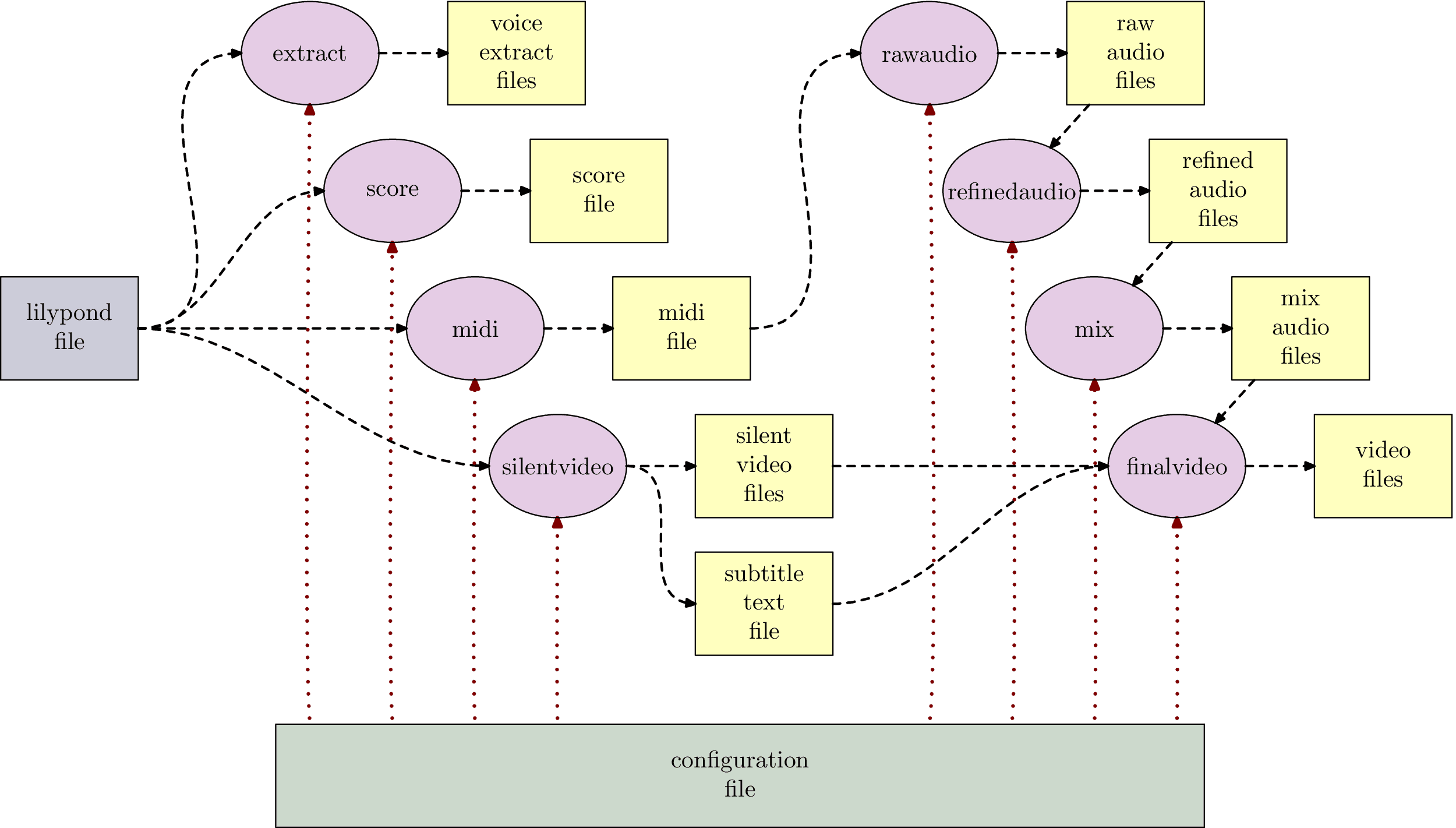
Bild 2 zeigt, wie das alles zusammenspielt. Dateien werden durch Kästen symbolisiert, die Bearbeitungsphasen durch Ovale.
Man erkennt ganz gut, dass die Phasen in der Regel voneinander abhängen: ich kann eine “rohe Audiodatei” nur dann erzeugen, wenn vorher schon eine MIDI-Datei erzeugt wurde.
Ebenso sieht man, dass die gesamte Prozesskette eigentlich nur zwei Inputs hat: die Lilyponddatei mit den Noteninformationen und die Konfigurationsdatei für allgemeine Einstellungen: die Namen der Stimmen, die MIDI-Instrumente, Informationen zur Humanisierungsmustern, der Typ der zu erzeugenden Videos, die Pan-/Volume-Einstellungen bei den Submixes usw.
Wenn einmal alles in den beiden Dateien erfasst wurde, dann gehen die Prozessschritte vollautomatisch und können daher gesamthaft oder auch einzeln durchgeführt werden, beispielsweise um irgendetwas auszuprobieren.
Aufgerufen wird das auf der Kommandozeile mit lilypondToBVC «phase» «konfigurationsdatei» also beispielsweise
lilypondToBVC score mySong-config.txt
Das Ganze skaliert übrigens wunderbar: komplexe Arrangements von realen Songs mit diversen Instrumenten laufen auf einem heutigen Rechner in 20 Sekunden komplett durch und natürlich viel schneller, wenn man dann nur einzelne Phasen durchlaufen will (zum Beispiel weil die Effektkette geändert wurde, was mit der Partitur an sich nichts zu tun hat).
Übersicht über die Dateiformate
Okay, also irgendwas mit Textdateien: wozu soll denn das gut sein?
Wer ganz früher schon mal Notensatz gemacht hat, weiß, dass man auch mit Textdateien hervorragend Stimmextrakte oder Partituren setzen kann. Berüchtigstes Beispiel war das SCORE-Programm von Leland Smith [Score] mit einer zwar sehr komplizierten Syntax, das aber lange Zeit sogar bei Notenverlagen (beispielsweise bei Schott) verwendet wurde, weil man damit tolle Ergebnisse produzieren kann. Diese gingen weit über das hinaus, was Programme mit graphischer Mausschubser-Oberfläche damals zustande bekamen.
Nachteil des textorientierten Vorgehens ist, dass man eben oft nicht direkt sieht oder sogar Einfluss darauf nehmen kann, wie der Notensatz aussieht (also kein WYSIWYG); Vorteil ist aber, dass man in solchen Notensatzsystemen zum Beispiel Teile seiner Stücke als Makros recyclen und sogar parametrieren kann (wie in einer Programmiersprache!), das ist gerade bei patternbasierter Musik — und auch viele Rock-/Popstücke sind das — sehr nützlich. Und dabei kommen dann oft mit wenig Aufwand passable Ergebnisse heraus.
Lilypond ist der derzeit prominenteste Vertreter dieser Programmgattung “textbasierter Notensatzsysteme”; es ist ein Open-Source-Programm, das per Kommandozeile Textdateien in Noten-PDF-Dateien, aber auch in MIDI-Dateien übersetzen kann.
Eine sehr einfache Lilyponddatei test.ly ist beispielsweise:
version "2.22.0"
tonleiter = relative c' { f4 g a b | c d e f | }
score {
tonleiter
}
Man sieht relativ viele Wörter mit einem Rückwärtsschrägstrich davor: das sind Lilypond-Kommandos. Damit wird zum Beispiel die Lilypond-Version auswählt (“version”) und die Partitur festgelegt (“score”). Die geschweiften Klammern dienen zur Gruppierung, das kennt man auch von einigen Programmiersprachen. Wichtig ist, dass man in Lilypond auch eigene Kommandos definieren kann: “tonleiter” ist definiert als eine ansteigende lydische F-Tonleiter mit Viertelnoten, und sie kann dann an anderer Stelle in der Partitur verwendet werden (mit Rückwärtsschrägstrich).
Das Kommando lilypond test.ly erzeugt aus diesem Text eine PDF-Datei, die man in Bild 3a sehen kann. Wir werden später lilypond nicht direkt verwenden, sondern auf Funktionen des LilypondToBandVideoConverter zurückgreifen, der lilypond hinter den Kulissen verwendet.
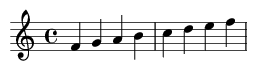 |
 |
|
| (a) | (b) |
Na toll: ich kann also eine Tonleiter mit kryptischen Kommandos setzen; willkommen im Jahr 1980…
Naja, wenn man zum Beispiel die Zeile mit
tonleiter
ersetzt durch
tonleiter transpose f c { tonleiter }
dann bekommt man die Originaltonleiter und eine um eine Quart nach unten transponierte lydische C-Tonleiter (Bild 3b). Das Ganze kratzt natürlich nur an der Oberfläche: es ist ein bißchen Programmieren von Musik, aber wenn man diese Abstraktion mag und damit umgehen kann, dann ist es eben sehr mächtig.
Gut, wir haben also eine Idee, wie man Noten in eine Textdatei eingibt und dann in PDFs übersetzen kann, aber wie kriegt man daraus Audio und Videos?
Dazu braucht man eine Konfigurationsdatei, die Informationen zu Stimmen, zu Instrumenten und etwaige Effekte enthält.
In einer Konfigurationsdatei stehen Schlüssel-Wert-Informationen, zum Beispiel, wie das Kommando für die Videogenerierung aussieht, oder eine Liste von Lautstärken für die diversen Instrumente.
Sehen wir uns an einen Beispiel an, wie das prinzipiell aussehen wird:
_initialTempo = 90
humanizedVoiceNameSet = "vocals"
voiceNameList = "vocals, guitar"
humanizedVoiceNameSet = humanizedVoiceNameSet ", drums"
measureToTempoMap = "{ 1 : " _initialTempo ", 20 : 67 }"
Man sieht also, dass eine Konfigurationsdatei einen relativ einfachen Aufbau hat, auf Details werden wir gleich eingehen.
Ein Fallbeispiel
Schauen wir uns das Vorgehen mal an einem Demobeispiel an.
Der Beispielsong ist ein Zwölftaktblues in E mit zwei Versen, Intro und Outro. Er ist zugegebenermaßen ziemlich schlecht, aber es geht ja nur darum zu zeigen, wie es funktioniert, ohne gleich Copyrightprobleme zu bekommen.
Wie beschrieben arbeiten wir mit zwei Dateien:
- einer Lilypond-Musikdatei, die die Musikfragmente enthält, die vom Generator verwendet werden, und
- einer songspezifischen Konfigurationsdatei mit Einstellungen für den Song (zum Beispiel dem Titel oder den Stimmnamen), sowie allgemeinen Einstellungen (zum Beispiel den Programmpfaden).
Oft verwendet man mehrere Konfigurationsdateien, zum Beispiel eine spezifische mit den Einstellungen des Songs (zum Beispiel dessen Name) und eine globale, songübergreifende mit allgemeinen Einstellungen (zum Beispiel mit dem Pfad eines MIDI-zu-Audio-Konverters, der für verschiedene Songs gelten wird). Wir verzichten aber in dem Beispiel auf diese Aufteilung, damit es einfach bleibt. (Das Ganze gilt natürlich auch für die Musik: wenn man irgendwelche Standardeinstellungen für die Notation hat, dann kann man diese auch in separaten Lilyponddateien ablegen.)
Im Folgenden erklären wir die Dateien in einzelnen Abschnitten nach Bedarf, also zum Beispiel die wesentlichen Teile der Konfigurationsdatei für die Stimmauszüge genau dann, wenn wir die Stimmauszüge erzeugen wollen.
Es geht aber erst einmal los mit den Noten. Und die müssen komplett sein, bevor wir überhaupt irgendetwas generieren können.
Die Lilyponddatei
In der Lilyponddatei wird zuerst festgelegt, dass wir englische Notennamen verwenden wollen (“ef” für es (= e flat), “as” für ais (= a sharp) und dass der Song im 4/4-Takt in E-Dur ist.
include "english.ly"
keyAndTime = { key e major time 4/4 }
Die Akkorde sind für ein Standardbluesschema mit einfachem Intro und Outro. Für die Stimmauszüge, Partitur und andere Darstellungen gibt es jeweils unterschiedliche Akkordschemata: das liegt daran, dass in manchen Darstellungen — beispielsweise in den Stimmauszügen — Wiederholungen vorkommen, während in anderen alle Takte linear expandiert wurden.
Für alle Instrumente gibt es dieselben Akkorde, und sie werden bei allen melodischen Instrumenten angezeigt; das könnte man aber anpassen.
chordsIntro = chordmode { b1*2 | }
chordsOutro = chordmode { e1*2 | b2 a2 | e1 }
chordsVerse = chordmode { e1*4 | a1*2 e1*2 | b1 a1 e1*2 }
allChords = {
chordsIntro repeat unfold 2 { chordsVerse }
chordsOutro
}
chordsExtract = { chordsIntro chordsVerse chordsOutro }
chordsScore = { chordsExtract }
b1*2 heißt, dass es ein H-Dur-Akkord ist (englisch “b”), mit Dauer einer ganzen Note (1/1) und dies über 2 Takte läuft (“*2”). Analog gibt es ein a2, das ist ein A-Dur-Akkord mit Dauer einer halben Note (1/2). Die Akkorde des Verses werden zweimal wiederholt (“repeat unfold 2”) und davor kommt das Intro, danach das Outro.
Kommen wir zu den Vocals: sie sind auch sehr simpel und mit einem Auftakt. Aus denselben Gründen wie bei den Akkorden gibt es eine Musikpassage für den Stimmauszug (vocalsExtract) und für die anderen Arten von Auszügen via (vocalsScore).
vocTransition = relative c' { r4 b'8 as a g e d | }
vocVersePrefix = relative c' {
e2 r | r8 e e d e d b a |
b2 r | r4 e8 d e g a g | a8 g4. r2 | r4 a8 g a e e d |
e2 r | r1 | b'4. a2 g8 | a4. g4 d8 d e | e2 r |
}
vocIntro = { r1 vocTransition }
vocVerse = { vocVersePrefix vocTransition }
vocals = { vocIntro vocVerse vocVersePrefix R1*5 }
vocalsExtract = {
vocIntro
repeat volta 2 { vocVersePrefix }
alternative {
{ vocTransition }{ R1 }
}
R1*4
}
vocalsScore = { vocalsExtract }
Wenn man sich vocalsExtract ansieht, sieht man, dass der erste Takt eine Pause ist (“r1”, r für rest), dann kommt eine vocTransition und dann zweimal ein Vers bestehend aus vocPrefix und vocTransition; das Outro besteht aus vier Takten Pause (“R1*4”, R für rest).
Die Vokalstimme hat auch Lyrics, die aber keinen Nobelpreis verdient haben. In lilypond werden dafür die Silben notiert und automatisch den Noten zugeordnet. Wegen der Wiederholungen mit Auftakten müssen die Lyrics etwas umsortiert werden.
vocalsLyricsBPrefix = lyricmode {
set stanza = #"2. " Don't you know I'll go for }
vocalsLyricsBSuffix = lyricmode {
good, be- cause you've ne- ver un- der- stood,
that I'm bound to leave this quar- ter,
walk a- long to no- ones home:
go down to no- where in the end. }
vocalsLyricsA = lyricmode {
set stanza = #"1. "
Fee- ling lone- ly now I'm gone,
it seems so hard I'll stay a- lone,
but that way I have to go now,
down the road to no- where town:
go down to no- where in the end.
vocalsLyricsBPrefix }
vocalsLyricsB = lyricmode {
_ _ _ _ _ _ vocalsLyricsBSuffix }
vocalsLyrics = { vocalsLyricsA vocalsLyricsBSuffix }
vocalsLyricsVideo = { vocalsLyrics }
Der Bass hämmert nur Achtelnoten raus. Wie oben gibt es einen Extrakt und eine Partiturversion mit Wiederholungen und eine komplett expandierte Version für den Rest (zum Beispiel für MIDI und Videos).
bsTonPhrase = relative c, { repeat unfold 7 { e,8 } fs8 }
bsSubDPhrase = relative c, { repeat unfold 7 { a8 } gs8 }
bsDomPhrase = relative c, { repeat unfold 7 { b8 } cs8 }
bsDoubleTonPhrase = { repeat percent 2 { bsTonPhrase } }
bsOutroPhrase = relative c, { b8 b b b a a b a | e1 | }
bsIntro = { repeat percent 2 { bsDomPhrase } }
bsOutro = { bsDoubleTonPhrase bsOutroPhrase }
bsVersePrefix = {
repeat percent 4 { bsTonPhrase } bsSubDPhrase bsSubDPhrase
bsDoubleTonPhrase bsDomPhrase bsSubDPhrase bsTonPhrase
}
bsVerse = { bsVersePrefix bsTonPhrase }
bass = { bsIntro bsVerse bsVerse bsOutro }
bassExtract = {
bsIntro
repeat volta 2 { bsVersePrefix }
alternative {
{bsTonPhrase} {bsTonPhrase}
}
bsOutro
}
bassScore = { bassExtract }
Die Gitarre spielt Arpeggi. Man sieht hier auch ganz gut, dass die Songfragmente verschiedener Instrumente in der Regel sehr ähnlich strukturiert sind.
gtrTonPhrase = relative c { e,8 b' fs' b, b' fs b, fs }
gtrSubDPhrase = relative c { a8 e' b' e, e' b e, b }
gtrDomPhrase = relative c { b8 fs' cs' fs, fs' cs fs, cs }
gtrDoubleTonPhrase = { repeat percent 2 { gtrTonPhrase } }
gtrOutroPhrase = relative c { b4 fs' a, e | <e b'>1 | }
gtrIntro = { repeat percent 2 { gtrDomPhrase } }
gtrOutro = { gtrDoubleTonPhrase | gtrOutroPhrase }
gtrVersePrefix = {
repeat percent 4 { gtrTonPhrase }
gtrSubDPhrase gtrSubDPhrase gtrDoubleTonPhrase
gtrDomPhrase gtrSubDPhrase gtrTonPhrase
}
gtrVerse = { gtrVersePrefix gtrTonPhrase }
guitar = { gtrIntro gtrVerse gtrVerse gtrOutro }
guitarExtract = {
gtrIntro
repeat volta 2 { gtrVersePrefix }
alternative {
{gtrTonPhrase} {gtrTonPhrase}
}
gtrOutro
}
guitarScore = { guitarExtract }
Abschließend das Schlagzeug: es begleitet mit einem relativ simplen Bluespattern plus -fills. Man muss hier als Stimmnamen myDrums verwenden, weil drums in Lilypond ein reserviertes Kommando ist. Es gibt keine Vorverarbeitung der Musikdatei, die dieses Problem irgendwie beheben könnte: die Fragmentdatei wird direkt in anderen Lilypond-Code eingefügt, daher muss sie der Lilypondsyntax genügen.
drmPhrase = drummode { <bd hhc>8 hhc <sn hhc> hhc }
drmOstinato = { repeat unfold 2 { drmPhrase } }
drmFill = drummode {
toml toml tomfl tomfl }
drmIntro = { drmOstinato drmFill }
drmOutro = drummode {
repeat percent 6 { drmPhrase } | <sn cymc>1 | }
drmVersePrefix = {
repeat percent 3 { drmOstinato } drmFill
repeat percent 2 { drmOstinato drmFill }
repeat percent 3 { drmOstinato }
}
drmVerse = { drmVersePrefix drmFill }
myDrums = { drmIntro drmVerse drmVerse drmOutro }
myDrumsExtract = {
repeat volta 2 {drmVersePrefix}
alternative {
{drmFill} {drmFill}
}
drmOutro }
myDrumsScore = { myDrumsExtract }
Wir sind mit der Lilypond-Fragmentdatei fertig. Wir haben jetzt folgendes ausnotiert:
- die Tonart und das Metrum,
- die Akkorde,
- die Lyrics, und
- die Stimmen für Vocals, Bass, Gitarre und Schlagzeug.
Leider war das oben keine vollständige Lilyponddatei, sondern nur ein Fragment mit der Nettoinformation, um die herum noch etwas Lilypond-Verwaltungstext ergänzt werden müsste. Das könnte man händisch machen und dann das Lilypond-Programm direkt nutzen oder aber stattdessen den ltbvc benutzen.
Weil das der LilypondToBandVideoConverter kann, benutzen wir ihn, aber dazu brauchen wir erst einmal eine Konfigurationsdatei…
Die Konfigurationsdatei für den LilypondToBandVideoConverter
Unsere Konfigurationsdatei enthält sowohl globale Einstellungen als auch solche für den Song. Die Konfigurationsvariablen sind in der Beschreibung vom ltbvc festgelegt und um diese von eigenen Hilfsvariablen zu unterscheiden, verwenden wir als Konvention, dass Hilfsvariablen mit einem Unterstrich beginnen, durch das Programm erkannte, “richtige” Konfigurationsvariablen fangen mit einem Kleinbuchstaben an.
Wenn die zu benutzenden Programme nicht im Programmpfad zu finden sind, sondern an speziellen Stellen stehen, muss man das angeben. Darauf kann man aber in der Regel verzichten, außer für spezielle Kommandos wie zum Beispiel midiToWavRenderingCommandLine, was wir später sehen werden, wenn wir zur Generierung der Audiodateien kommen. Diese Kommandozeile muss man beispielsweise deshalb angeben, weil in ihr der Pfad zu dem verwendeten Soundfont vorkommt, den der ltbvc nicht ohne Weiteres erraten kann.
Andere globale Einstellungen definieren Pfade für Dateien oder Verzeichnisse, aber für die meisten können wir wiederum die Standards nutzen. Nur sollen die temporären Dateien für Lilypond in das Unterverzeichnis “temp” gehen, die generierten PDF- und MIDI-Dateien in das Unterverzeichnis “generated” des aktuellen Verzeichnisses und Audiodateien nach “mediafiles”. Diese Verzeichnisse werden nicht automatisch angelegt; sie müssen existieren, bevor man den ltbvc startet.
tempLilypondFilePath = "./temp/temp_${phase}_${voiceName}.ly"
targetDirectoryPath = "./generated"
tempAudioDirectoryPath = "./mediafiles"
Der Song ist charakterisiert durch seinen Titel und den Dateinamenspräfix für die erzeugten Dateien.
title = "Wonderful Song" fileNamePrefix = "wonderful_song"
Die wesentliche Information zum Song ist die Liste aller Stimmen. Darauf beziehen wir uns später an diversen Stellen, insbesondere werden aber damit die Namen der Stimmauszüge, die Reihenfolge der Stimmen in der Partitur und in der MIDI-Datei festgelegt.
voiceNameList = "vocals, bass, guitar, drums"
Das Tempo ist durchgängig 90bpm ab Takt 1; man könnte auch noch Tempowechsel festlegen, aber das ist hier nicht nötig.
measureToTempoMap = "{ 1 : 90 }"
Einstellungen für Stimmauszüge und Partitur
Für Stimmauszüge und Partitur wird eine kleine Notiz zum Arrangeur erstellt.
composerText = "arranged by Fred, 2019"
Für die Lyrics müssen wir festlegen, bei welcher der Stimmen sie stehen, und ob mehrere parallele Lyrics verwendet werden. In unserem Fall sind es jeweils zwei Parallelspuren beim Stimmextrakt für “vocals” (e2) und bei der Partitur (s2) sowie eine Spur beim Video (v).
voiceNameToLyricsMap = "{ vocals : e2/s2/v }"
Ebenso passen die Standardeinstellungen für die Notation: dann wird für Schlagzeug ein Schlagzeugsystem verwendet, Bass und Gitarre haben um eine Oktave nach oben beziehungsweise unten transponierte Schlüssel und bei Schlagzeug gibt es gar keinen Schlüssel. Die Akkordsymbole kommen in den Auszügen für alle Melodieinstrumente vor sowie über den “vocals” in der Partitur und in den Videos. Würde man das ändern wollen, gäbe es dafür spezifische Variablen.
 |
 |
|
| (a) | (b) | |
 |
 |
|
| (c) | (d) |
Die Bilder 4a-d zeigen die resultierenden Stimmauszüge nach dem Kommando
lilypondToBVC --phases extract wonderful_song-config.txt
Für die Partitur gibt man das Kommando
lilypondToBVC --phases score wonderful_song-config.txt
Die resultierende Partitur zeigt Bild 5. Man erkennt ganz gut die Entsprechungen der Notendarstellungen zur Repräsentation in Lilypond aus dem vorigen Kapitel.
 |
 |
Einstellungen für die MIDI-Datei
Aus derselben Lilypond-Datei könnte man auch die MIDI-Datei erzeugen; das kann schon lilypond selbst, es ist also nicht besonders überraschend.
Aber die von Lilypond erzeugte MIDI-Datei klingt sehr statisch; daher gibt es diverse Einstellungen im ltbvc, um das zu verbessern. Zuallererst werden den einzelnen Stimmen MIDI-spezifische Informationen zugeordnet. Diese werden über ihre jeweilige Position in ihrer Liste dem entsprechenden Eintrag in der Stimmliste zugeordnet. Das heißt, dass beispielsweise dem dritten Eintrag in voiceNameList (hier “guitar”) der dritte Eintrag in midiVolumeList (hier 70) als MIDI-Lautstärke zugeordnet ist. Es bietet sich also an, die Einträge passend zueinander auszurichten wie hier:
voiceNameList = "vocals, bass, guitar, drums" midiInstrumentList = " 18, 35, 26, 13" midiVolumeList = " 100, 120, 70, 110" panPositionList = " C, 0.5L, 0.6R, 0.1L" reverbLevelList = " 0.3, 0.0, 0.0, 0.0"
Schauen wir uns einen Eintrag an: beispielsweise wird der Bass mit General-MIDI-Instrument 35 gespielt (das wäre laut Definition des “General-MIDI-Standards” ein “fretless bass”), er hat Lautstärke 70 (von maximal 127 Einheiten), ist im Stereospektrum bei 50% links angeordnet und hat keinen Nachhall (zumindest in der MIDI-Datei, bei der nachfolgenden Audioverbesserung werden wir das nachholen).
Darüber hinaus kann man eine “MIDI-Humanisierung” auf die MIDI-Datei anwenden, die dann auch für die daraus erzeugten Audiodateien gilt. Sie ist natürlich meist songabhängig.
Humanisierungen werden als Muster definiert; dabei werden relativen Positionen im Takt jeweils sowohl eine Änderung in ihrer Notenanschlagstärke (der “Velocity”) als auch der Zeitposition (vor oder zurück) zuordnen. Diese Änderungen sind zufällig und relativ zu einem Referenzwert. Bei der Velocity gibt man als Referenzwert einen Faktor in der Nähe von 1.0 an, mit dem die Anschlagstärke der Ausgangsnote multipliziert wird. Bei der Zeit ist der verwendete Referenzwert der ursprüngliche Notenzeitpunkt. Dann kommt eine positionsunabhängige Variation der Velocity (“SLACK”) und eine positionsabhängige Zeitvariation, jeweils zufällig und mit einer Verteilung, die kleine Variationen bevorzugt.
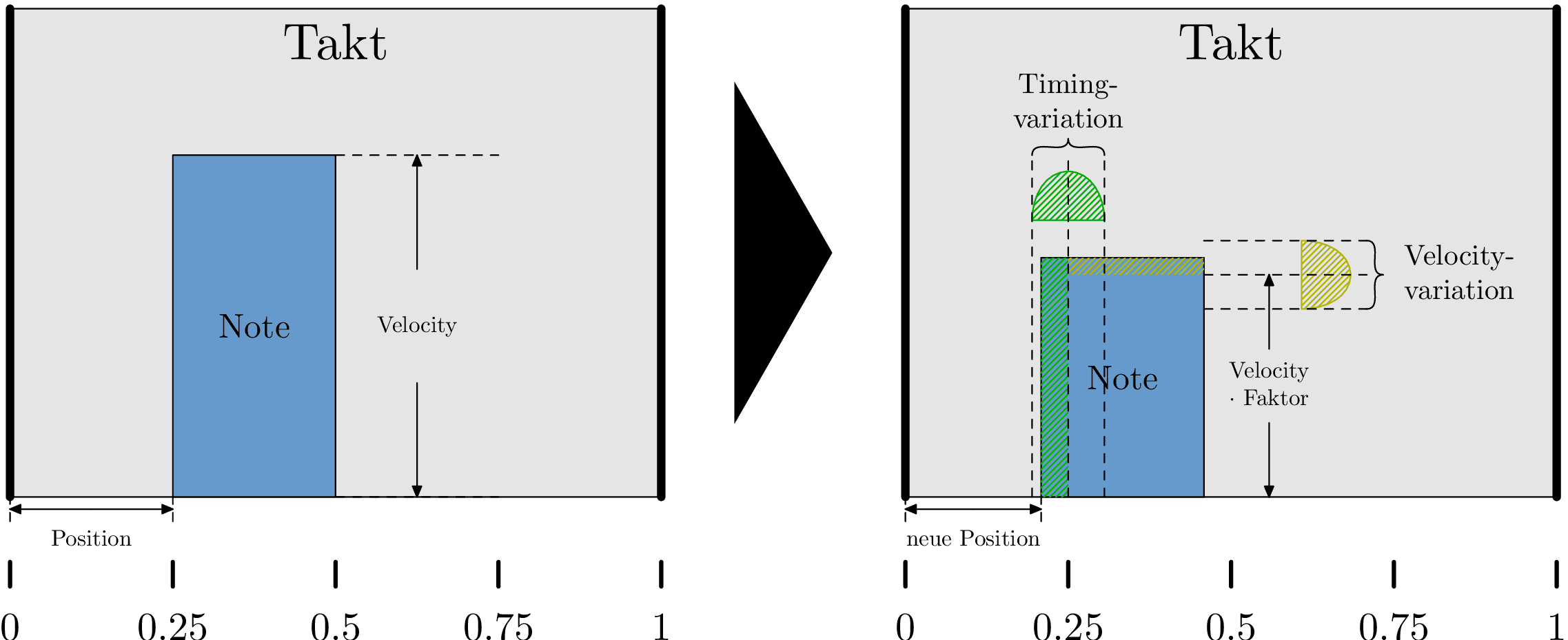
Bild 6 zeigt schematisch wie die Humanisierung einer Note an einer Position in einem Takt erfolgt: ihre Velocity wird mit einem positionsabhängigen Faktor multipliziert und dann mit einem zufälligen Schlupf innerhalb einer positionsunabhängigen Variationsbreite versehen. Die Startzeit wird variiert um eine positionsabhängige Variationsbreite. Die Glockenkurven im Diagramm stellen symbolisch dar, dass große Variationen in dem vorgegebenen Intervall unwahrscheinlicher sind als kleine Variationen.
Wir verwenden für unseren Song nur ein Humanisierungsmuster: einen Rock-Groove mit präzisen Schlägen auf 2 und 4 (also bei 25% und 75% eines Taktes) und geringer Variation im Timing für andere Positionen in einem Takt. Diese Timing-Variationen sind sehr subtil und liegen im Beispiel maximal bei 0,3 Rastereinheiten (beim dritten Schlag). Das Raster wird als 32stel-Note festgelegt; das heißt die Variation ist maximal eine 32stel-Note ×0,3. Für die Velocity gibt es einen harten Akzent auf zwei und einen leichteren Akzent auf vier, die anderen Positionen sind schwächer.
Es gibt in unserem Beispiel keine individuellen Variationsfaktoren pro Instrument (das könnte man auch einstellen, wenn ein Schlagzeug beispielsweise ein genaueres Timing haben soll als der Bass); daher haben alle humanisierten Instrumente gleichartige (aber nicht identische!) Variationen in Timing und Velocity.
Solche Humanisierungsstile werden als Variablen mit Namenspräfix humanizationStyle in der Konfigurationsdatei angegeben:
humanizationStyleRockHard =
"{
" 0.50: 0.98/0.3, 0.75: 1.1/0,"
" OTHER: 0.85/0.25,"
" SLACK:0.1, RASTER: 0.03125 }"
Für den Song wird dann festgelegt, ab welchem Takt ein Humanisierungsstil verwendet wird und für welche Stimmen; hier wird der obige Stil durchgängig ab Takt 1 benutzt und das für alle Stimmen außer den Vocals:
humanizedVoiceNameSet = "bass, guitar, drums"
measureToHumanizationStyleNameMap =
"{ 1 : humanizationStyleRockHard }"
Wir wollen auch noch eine Einzählung um zwei Takte (weil wir dazuspielen wollen 😉):
countInMeasureCount = 2
Mit all den bisherigen Informationen kann die MIDI-Datei komplett erstellt werden mit
lilypondToBVC --phases midi wonderful_song-config.txt
Bild 7 zeigt zum Vergleich die MIDI-Datei direkt aus Lilypond und die nach der Humanisierung. Man hört ganz gut, wie die Humanisierung dafür sorgt, dass auf die Schläge 2 und 4 akzentuiert wird.
Damit der Vergleich nicht vom lokalen MIDI-Player beim Leser abhängig ist, wurde für beide MIDI-Dateien jeweils mit demselben Soundfont eine FLAC-Datei erzeugt.
Okay, das klingt etwas besser, aber immer noch nicht toll. Da müssen wir per Audionachbearbeitung später noch nachbessern…
Einstellungen für die Video-Generierung (ohne Audio)
Wir haben jetzt schon mal die Partitur und die Stimmauszüge als PDF-Dateien und eine MIDI-Datei. Wenn wir am Schluss ein Video mit Audiospuren wollen, dann brauchen wir zuallererst mal das Video. Die Grundidee ist simpel: wir expandieren alle Wiederholungen, “fotographieren” die Noten dann seitenweise ab und zeigen im Video jede Notenseite so lange an, wie die entsprechende Passage dauert. Damit man sich beim Playback nicht auf der Seite verliert — ein Orchestermusiker bräuchte das natürlich nicht 😉 —, wird die aktuelle Taktnummer als Untertitel eingeblendet.
Welche Stimmen in den Videos vorkommen sollen, wird durch die Konfiguration bestimmt. Für ein “Karaoke-Video” werden es nur die Vokalstimmen sein, aber man könnte auch die gesamte Partitur nehmen oder irgendetwas dazwischen.
Insgesamt gibt es zwei Dinge, die man konfigurieren muss:
- ein oder mehrere Videoziele, in denen beschrieben ist, welche Auflösung, Orientierung, Ränder usw. das Video haben soll und
- ein oder mehrere Videoarten, in denen beschrieben wird, welche Stimmen in den Videos vorkommen sollen und wie die Dateinamen dafür aussehen.
Man kann also ein Video erzeugen für ein Tablet im Hochformat (als Videoziel), ein anderes für ein Smartphone im Querformat (als Videoziel) und beim ersten wird die Partitur ausgegeben (definiert über eine Videoart) und beim zweiten nur die Vocals (auch definiert über eine Videoart).
Für das Beispiel nehmen wir ein Videoziel und eine Videoart; dass das Ziel dabei “tablet” heißt, soll nicht verwirren: es ist nur ein Video mit einer bestimmten Größe (768 x 1024) und Auflösung (132ppi), es läuft natürlich auf jeder Plattform (die mit dem Format an sich zurechtkommt 😉).
videoTargetMap = "{
"tablet: {
" height: 1024,"
" width: 768,"
" topBottomMargin: 5,"
" leftRightMargin: 10,"
" scalingFactor: 4,"
" frameRate: 10.0,"
" mediaType: 'Music Video',"
" systemSize: 25,"
" subtitleColor: 2281766911,"
" subtitleFontSize: 20,"
" subtitlesAreHardcoded: true } }"
Bild 8 zeigt, welche Maße ein Videoziel festlegen; sie sind jeweils in Pixeln oder Pixeln pro Inch angegeben.

Die Videoart benutzt dieses Zielformat und legt darüber hinaus noch fest, dass sowohl Vocals als auch Gitarre im Video vorkommen und dass diese Dateien als “./mediafiles/SONGNAME-tblt-vg.mp4” abgelegt werden.
videoFileKindMap = "{
"tabletVocGtr: {
" fileNameSuffix: '-tblt-vg',"
" directoryPath: './mediaFiles' ,"
" voiceNameList: 'vocals, guitar' } }"
In beiden Listen könnten auch mehrere Einträge vorkommen, das wäre aber dann eine fortgeschrittene Nutzung…
Wenn man kein Videoziel definiert, wird als Standard-Videoziel (das zufälligerweise auch “tablet” heißt) ein Video mit 640×480 Pixel und Auflösung von 64ppi genommen. Die Standard-Videoart verwendet “tablet” und gibt in diesem Video nur die Vocals aus.
Das Kommando
lilypondToBVC --phases silentvideo wonderful_song-config.txt
erzeugt zwei Dateien: ein stummes Video und eine Untertiteldatei, die von mehreren Videos genutzt werden kann (Bild 9).
Zwischenfazit
Wir haben jetzt schon Einiges aus der Lilypond-Datei herausgesaugt:
- Stimmauszüge und die Partitur (als PDF-Dateien),
- eine (etwas humanisierte) MIDI-Datei, und
- ein stummes Notenvideo und die Taktnummern als Untertitel.
Wie man in Bild 10 erkennt, sind wir jetzt mit der Lilyponddatei durch, der Rest entsteht aus obigen Zwischenergebnissen. Das Notationsvideo braucht jetzt beispielsweise noch Audiospuren (idealerweise mit unterschiedlichen Stimmen).
|
Vorverarbeitung (preprocess)
|
Nachverarbeitung (postprocess)
|
|
|
||
Und es wird nicht besser: auch die Berechnung der Audiospuren und das Einbinden in das Video wird wiederum über die Kommandozeile erledigt, wobei wir allerdings über die Konfigurationsdatei auch wieder alles entsprechend einstellen werden.
Einstellungen für die Audio-Generierung
Aus der MIDI-Datei werden die einzelnen Stimmen in Audiodateien umgewandelt. Für die Kommandozeile gibt es leider nicht viele Programme, die so etwas können, halbwegs flexibel sind und auch noch eine gute Klangqualität abliefern. Ein relativ gängiges Programm dafür ist fluidsynth, das sogenannte Soundfonts verwendet und für die üblichen Plattformen verfügbar ist. Soundfonts enthalten gesampelte Instrumente (zusammen mit Hüllkurvendefinitionen, Modulatoren usw.); man bekommt sehr brauchbare und insbesondere auch solche, die alle General-MIDI-Instrumente enthalten (wie beispielsweise den eingangs erwähnten FluidR3_GM.sf2).
Dem ltbvc ist aber das Transformationsprogramm eigentlich egal, und es muss auch nicht mit Soundfonts arbeiten. Man könnte daher auch ein anderes verwenden, solange es irgendwie auf seiner Kommandozeile den Namen einer MIDI-Eingabedatei und den einer Audio-Ausgabedatei erwartet.
Unabhängig davon muss man in der Konfigurationsdatei das Muster für die Kommandozeile dieses midiToWavRenderingCommands vorgeben. Selbst wenn man fluidsynth verwenden will, so kommt in dessen Kommandozeile zwingend der Pfad zum verwendeten Soundfont vor, und dafür gibt es keinen Standardwert. Darüber hinaus gibt es darin auch noch Platzhalter für die MIDI-Eingabedatei und die WAW-Ausgabedatei. Wir gehen in unserem Beispiel — wie beschrieben — davon aus, dass Fluidsynth als MIDI-zu-WAV-Konverter genutzt wird.
_soundFonts = "/usr/local/midi/soundfonts/FluidR3_GM.SF2"
midiToWavRenderingCommandLine =
"fluidsynth -n -i -g 1 -R 0"
" -F ${outfile} " _soundFonts " ${infile}"
Das Kommando
lilypondToBVC --phases rawaudio wonderful_song-config.txt
erzeugt vier Audiodateien für Drums, Gitarre, Vocals und Bass. Dies sind wirklich “rohe” Instrumentenspuren, weil ein etwaiger Hall im MIDI-Instrument bei der Generierung deaktiviert wird.
Einstellungen für die Audio-Nachbearbeitung
Okay, diese rohen Audiospuren muss man wirklich noch nachbessern.
Wir brauchen also wieder ein Programm, das via Kommandozeile Audioeffekte auf diese Instrumentenaudiospuren anwenden kann.
SoX ist ein derartiges Programm, mit dem man Effektketten festlegen kann. Beispielsweise wendet das Kommando
sox input.wav output.wav highpass 80 2q reverb 50
einen Hochpassfilter zweiter Ordnung bei 80Hz mit Breite 2Q gefolgt von einem mittleren Nachhall auf Datei input.wav an und speichert das Resultat in Datei output.wav.
SoX hat diverse dieser Effekte, und sie alle können für die Klangformung verwendet werden. Es würde den Platz sprengen, hier auf alle Möglichkeiten einzugehen; detaillierte Information findet man auf der SoX-Webseite [SoX].
Natürlich könnte man ein anderes Audioprogramm für die Kommandozeile benutzen, in dem man die Variable audioProcessor einfach entsprechend belegt. Aber das wäre wiederum eine Expertenlösung…
Jeder Audiotrack aus der Phase “rawaudio” wird über stimmspezifische Einstellungen in der Konfigurationsdatei mit Effekten versehen. In der Phase “refinedaudio” wird beispielsweise aus der Datei “bass.wav” für den Bass die Datei “bass-processed.wav”; diese Dateinamen werden vom Werkzeug fest vorgegeben.
Wir brauchen also nur die Transformationseffekte pro Stimme selbst festzulegen. Dafür werden sogenannte Soundstile verwendet. Deren Namen ergeben sich aus dem Präfix “soundStyle” gefolgt vom Stimmnamen (zum Beispiel “Bass”) und von einem Wort, das die Variante kennzeichnet zum Beispiel (“Hard”). In unserem Beispiel käme dann der Name “soundStyleBassHard” heraus.
Man kann sich so eine Bibliothek von Effektketten in einer zentralen Datei anlegen; für einen Song kann man aber auch spezifische Stile in der Konfigurationsdatei des Songs festlegen.
Genau das machen wir jetzt: wir legen vier Stile fest “Bass-Crunch”, “Drums-Grit”, “Guitar-Crunch” und “Vocals-Simple”.
Der Bass wird über einen Kompressor mit 30ms Attack, 100ms Release und einem 4:1-Verhältnis mit Schwelle bei -20dB komprimiert, dann kommt ein Hochpass zweiter Ordnung bei 60Hz, ein Tiefpass zweiter Ordnung bei 800Hz und ein Equalizer bei 120Hz mit +3dB (alle jeweils mit einer Oktave Bandbreite) abschließend gefolgt von einem Hall mit 60%Anteil und diversen Steuerparametern.
soundStyleBassCrunch =
" compand 0.03,0.1 6:-20,0,-15"
" highpass -2 60 1o lowpass -2 800 1o equalizer 120 1o +3"
" reverb 60 100 20 100 10"
Die anderen Stile sehen ähnlich aus, Details kann man der SoX-Dokumentation entnehmen:
soundStyleDrumsGrit = "overdrive 4 0 reverb 25 50 60 100 40"
soundStyleGuitarCrunch =
" compand 0.01,0.1 6:-10,0,-7.5 -6"
" overdrive 30 0 gain -10"
" highpass -2 300 0.5o lowpass -1 1200"
" reverb 40 50 50 100 30"
soundStyleVocalsSimple = " overdrive 5 20"
Und die Zuordnung erfolgt — wie oben bei der MIDI-Definition — in den Spalten der Stimmnamen. In der Variable soundVariantList werden nur die Stilvarianten angegeben, also wie folgt:
voiceNameList = "vocals, bass, guitar, drums" ... soundVariantList = "SIMPLE, CRUNCH, CRUNCH, GRIT"
Wenn man diese Stile anwendet mit dem Kommando
lilypondToBVC --phases refinedaudio wonderful_song-config.txt
entstehen vier weitere, nachbearbeitete, Instrumentenaudiospuren für Drums, Gitarre, Vocals und Bass, in denen die Effektketten auf die Rohdateien angewendet wurden. Bild 12 zeigt rohe und bearbeitete Audiospuren im Vergleich.
Mischen in Audiotracks für das Notationsvideo
Diese Instrumentenaudiospuren könnte man prinzipiell direkt in einem passenden Mehrspurkontext einsetzen, also zum Beispiel als Stems in einem entsprechenden Audio-Player. Dort könnte man dann auch diejenigen Tracks auswählen, die man gerade benötigt und die anderen stummschalten.
Wir wollen aber keine Spezialsoft- oder -hardware verwenden, sondern ein klassisches Programm zur Videowiedergabe auf einem beliebigen Gerät. In der Regel kann man beim Abspielen eines Videos aber nicht mehrere Tracks parallel aktivieren, sondern nur einen einzelnen (beispielsweise um bei einem Film unter verschiedenen Sprachspuren eine einzelne auszuwählen).
Der Behelf ist dann, dass man für jede interessante Kombination von Instrumentenaudiospuren einen Submix erzeugt und diesen in einem Audiotrack des Videos ablegt. Bei fünf Instrumenten hätte man prinzipiell 32 Submixe; damit wäre jede Kombination abgedeckt, aber das wird man in der Regel nicht machen, weil es relativ viel Speicherplatz in der Ausgabedatei erfordert; stattdessen wird man sich auf eine gewisse Auswahl beschränken.
Um diese Auswahl festzulegen, werden einzelnen Tracks definiert mit Name, Instrumentstimmen und jeweilige Lautstärken wie folgt
_voiceNameToAudioLevelMap =
"{ vocals : -4, bass : 0, guitar : -6, drums : -2 }"
audioTrackList = "{
"all : {
" audioGroupList : bass/vocals/guitar/drums,"
" languageCode: deu,"
" voiceNameToAudioLevelMap : " _voiceNameToAudioLevelMap "},"
"novoice : {
" audioGroupList : bass/guitar/drums,"
" languageCode: eng,"
" voiceNameToAudioLevelMap : " _voiceNameToAudioLevelMap "},"
"}"
Es soll also im Video zwei Tracks geben: einer mit allen Stimmen und einer mit allen Stimmen bis auf die Vocals. Die Lautstärken der Stimmen sind in einer Tabelle _voiceNameToAudioLevelMap mit Dezibel-Einträgen angegeben. Beide Tracks nutzen die gleichen relativen Lautstärken; das könnte man auch variieren.
Auffällig ist, dass man einen “languageCode” angeben muss: das ist der Sprachkode, der angibt, unter welcher “Audiosprache” ein Track einsortiert wird. Man braucht das, weil es viele Videoplayer gibt, die weder Namen noch Beschreibung für Tracks anzeigen können, sondern nur eine Sprache (also zum Beispiel “English” statt “novoice”). Es ist also ein Behelf; die Sprachzuordnung ist völlig willkürlich, man muss sich halt beispielsweise merken, dass die Karaokespur ohne Vocals “Englisch” ist.
Wenn man das Kommando
lilypondToBVC --phases mix wonderful_song-config.txt
entstehen zwei Audiotracks mit den entsprechenden Mischungen.
Kombination der Audiospuren mit dem Notationsvideo
Letzter Schritt: wir kombinieren jetzt das stumme Video mit den Audiospuren.
Es wurde schon in den vorhergehenden Abschnitten in der Konfigurationsdatei alles definiert, was wir benötigen. Wesentlich sind die Einträge für videoFileKindMap und audioTrackList. Sollten in der videoFileKindMap mehrere Videoziele definiert sein, dann werden auch mehrere Videos erzeugt, die aber jeweils alle Spuren deraudioTrackList enthalten.
Mit dem Kommando
lilypondToBVC --phases finalvideo wonderful_song-config.txt
entsteht eine Videodatei, die in Bild 14 zu sehen ist.
Zusammenfassung
Uff, das war jetzt wirklich ein wilder Ritt.
Wir haben jetzt einigermaßen mühsam (aber immerhin!) folgendes hinbekommen: aus einer Textdatei für ein Arrangement und einer Konfigurationsdatei werden mit einigen Open-Source-Programmen und dem Koordinationsprogramm LilypondToBandVideoConverter automatisch (!)
- Stimmauszüge,
- Partitur,
- MIDI-Datei,
- Audio-Stems,
- diverse Submixe als Audiodateien und schließlich
- ein Notationsvideo mit diversen Audiospuren, aus denen man die benötigte auswählen kann.
Der vorgestellte Ansatz ist relativ ausgefeilt, und man kann damit brauchbare Ergebnisse erzielen. Allerdings muss man sich auf eine Arbeitsweise einlassen, in der man Korrekturen in Textdateien macht, man dann irgendeinen Übersetzer laufen läßt und erst danach sehen kann, ob die Korrekturen okay sind oder auch nicht.
Gegenrede und Vertröstung
Okay, Fredi, das klingt ja ganz lustig und schrullig. Früher in den 70er-Jahren hat meine Omi auch die Lochkarten abgegeben und nach fünf Stunden dann in einem Papierlisting gesehen, dass ihr Programm doch nicht so funktioniert, wie sie dachte. Edit-Compile-Run, so hieß das früher.
Aber so arbeitet man doch heute nicht mehr, jetzt geht alles in Echtzeit!!
Gemach, gemach: in Teil 2 werden wir sehen, wie der Ansatz auch mit einer DAW zusammenzubringen ist, und man damit interaktiver und vielleicht auch effizienter arbeiten kann… FÜR TEIL 2 HIER KLICKEN





Nerd ! 🙂👍
Ich bin zutiefst beeindruckt. Ich benutze Python auch für eine andere Geschichte, aber die Befehle muss ich nur reinkopieren und was ich schreibe, sind drei Zeilen, immer die gleichen bis auf ein Name. Ich konnte auch Erfahrung mit ein paar Statistikprogrammen sammeln. Von daher kann ich mir Ansatzweise vorstellen, was das für eine Arbeit ist. Aber das Ergebnis gibt dir recht. Ach da steht es Ja, It-ler bist. Dem Ingenieur ist nichts zu schwör. Beeindruckend und sehr kreativ. Ich mag es, wenn Geräte zweckentfremdet werden. Beneidenswerte Skills ! Chapeau!
@Sven Rosswog Hallo Sven,
danke für Deinen freundlichem Kommentar! IT-ler sind halt doch oft Nerds, daher ist der Titel sicher nicht ganz daneben!
Ich muss mich bei Dir entschuldigen, manchmal bin ich mit Dir in Diskussionen nicht so freundlich umgesprungen, daher beschämt mich Dein Lob natürlich zutiefst.
Aber vielleicht sollten wir mal bei einem Bier beim Experience Day – wenn Corona irgendwann mal wirklich vorbei sein sollte – unsere unterschiedlichen Herangehensweisen an das Musizieren und die Welt im Allgemeinen mal abgleichen. Geht auf mich…
Viele Grüße
Fredi
Hallo zusammen,
falls hier im Kreis doch Experten für Lilypond vertreten sein sollten eine kleine Information: durch die – im Übrigen sehr sorgfältige, vielen Dank dafür! – Endredaktion sind leider offenbar in den farblich unterlegten Dateiauszügen die Rückwärtsschrägstriche verloren gegangen. D.h. es muss vor Bild 3 beispielsweise „score { \tonleiter }“ heißen und ähnlich.
Das ist jetzt nicht schlimm; ich hoffe, die Grundidee wird trotzdem klar, auch wenn die Syntax etwas holpert…
Gruß
Fredi
Sehr lässig, die Backingtrack-Idee alleine ist schon großartig, dass aber mit Video zu verknüpfen ist grenzgenial. Muss ich bei Gelegenheit ausprobieren! :)
Für SOWAS liebe ich dann amazona.de wieder sehr 🤓 Die Anwendung tangiert mich selbst nur wenig bis kaum, aaaaber die Problemstellung ist interessant und die deine Lösung noch interessanter. Richtig feine Lektüre! Ich code auch gern in der Freizeit herum, nutze unterschiedlichste Plattformen. dafür und das alles aus einem Grund; Kurzweil, die den Geist am Laufen hält 😂
Wow, beeindruckend! Der Ansatz ist zwar wirklich etwas nerdig, aber als Linuxuser und python Entwickler kann ich nur sagen: Hut ab :)
Verrückter Kerl! Und das ist durchaus positiv gemeint 😄