
PPG lernt sprechen
Wolfgang Palm ist vielen Musikern als Erfinder der Wavetable-Synthese und als Gründer der Firma PPG bekannt. In den letzten Jahren sind die Instrumente Wavemapper und Wavegenerator von ihm entwickelt worden, die das Erbe der legendären Wavetable-Synthese auf Computer (VST, AU) und mobile Geräte (iOS) übertragen hat. PPG Phonem ist nun als Vocal Synthesizer neu hinzugekommen.
Der Name weist bereits auf die Erzeugung menschlicher Sprachlaute hin. Was verbirgt sich dahinter?

Phonem GUI
Klangerzeugung
Die Geschichte der Erzeugung künstlicher menschlicher Sprachlaute reicht Jahrhunderte zurück. Bereits im 18. Jahrhundert wurde versucht, menschliche Laute mechanisch mit Sprechmaschinen nachzubilden. Computergestützte Sprachsynthese gibt es seit den 60er Jahren des letzten Jahrhunderts.
Das „Phonem“ an sich definiert sich als die kleinste bedeutungsunterscheidende akustische Einheit des Lautsystems einer Sprache.
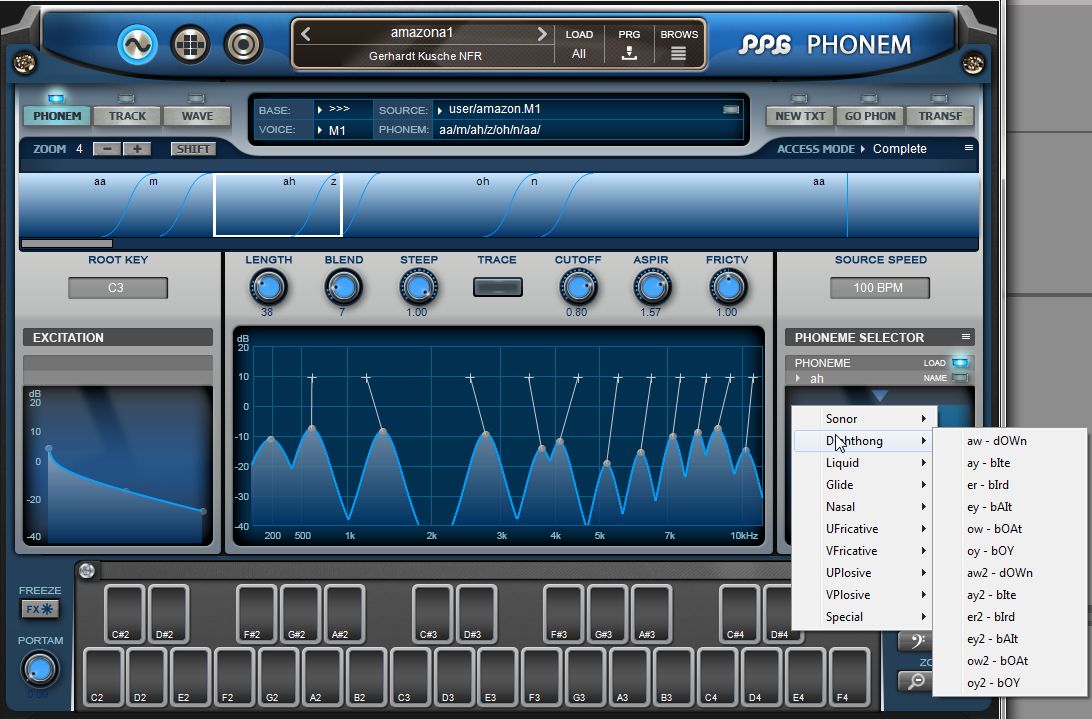
PPGs Phonem nutzt als Klangquelle zunächst den so genannten Excitator. Hier werden statt Oszillatorschwingungen künstliche Laute, also Phoneme erzeugt. Diese sind auf die englische Sprache ausgerichtet und werden durch einige französische und deutsche Besonderheiten in der Aussprache ergänzt (französische nasale Laute oder das deutsche „-ch“ wie in „ich“ und „auch“).
Beispiel für Phoneme
Sortiert sind diese in einer übersichtlichen Datenbank und jeweils mit einem Aussprachebeispiel versehen. So kann der passende Ausdruck schnell gefunden werden. Die Schreibweise der Phoneme ist nach dem „Carnegie Mellon University (CMU) Pronouncing Dictionary“ ausgelegt, zum Beispiel:
- ih – wie in bit
iy – wie in beat
ay – wie in bite
er – wie in bird
Die Aussprachebeispiele beschreiben das jeweilige Phonem. So unterscheiden sich zum Beispiel unterschiedlich scharfe S-Laute oder die Formung von Vokalen. Durch die Beispielwörter ist der Grundcharakter sofort begreifbar und man findet schnell die passenden Segmente.
Hi, klar gibt es davon eine Demoversion:
http://wolfgangpalm.com/phonem_demos.html
beste Grüße
Max
@Max Van Allen Hallo Max, dann ist die Demoversion erst vor kurzem dazugekommen. Danke für die Info!
Auf der Produktseite sind bereits Demoversionen für Mac&PC erhältlich:
http://wolfgangpalm.com/phonem_demos.html
Hallo Craven, mittlerweile gibt es eine Demoversion. Danke für die Info.
In den 90s wollte ich mal Phoneme sampeln und dann zusammensetzen, habe es jedoch nie umgesetzt. Die Resultate und Möglichkeiten wären jedoch nie an diesen PPG rangekommen und wahrscheinlich nicht sehr brauchbar gewesen….
Hi Gerhardt,
wie sieht es denn mit dem Kopierschutz von dem Teil aus? Bei meinen letzten Checks was das ein recht eingeschränktes C/R-Verfahren, oder so.
Das einzige was mich bisher abgehalten hat die Software zu kaufen.
PS: auch eine geniale Software zum Thema ist chipspeech von Plogue.com – eine Emulation der ganzen alten Sprachcomputer u.a. mit dem „legendäre“ Speak n Spell und so.
Grüße,
M.
@Markus Schroeder Hallo Markus,
eine Online-Aktivierung ist notwendig, ja.
mir kam bei den meisten klangbeispielen sofort kraftwerk in den sinn, auch sonst klingt es doch arg „vocoderig“. die sprachverständlichkeit eines vocoders ist sehr abhängig von der anzahl der bänder, mit denen er ausgestattet ist.
ein nettes programm, neuartiges scheint es aber nicht zu bieten – zumindestens den klangbeispielen nach.
Beim dem PPG Phonem handelt es sich keinesfalls „nur“ um einen „vocoder-ähnlichen“ Voicesynthesizer. Dies hier ist ein vollständiger Synthesizer, mit dem sich u.a. hervorragende Chors, Pads, Strings, FXs als auch natürlich phonetische Silben, -Worte, etc., synthetisieren lassen. Gerade Voice-ähnliche Chors/Strings können hervorragend realisiert werden. Das Plug-In dient in erster Linie als Instrument im Sinne eines Synthesizers und nicht (wie einige es ggf. in erster Linie interpretieren könnten) ausschließlich als Effekt-Plug-In / Speechsynth. Experimentiert etwas mit dem Teil .. schaut euch den Presetaufbau an .. es kann viel mehr, als der Anschein auf den ersten Blick trügerlich zu vermitteln vermag.
Demo 4 ist sehr beeindruckend :-)
Im Vergleich zu anderen wäre ja mal interessant. Zum Beispiel: Autotune, TC Helicon usw. Hier gibt es auch noch ein interessantes Plugin. PitchProof, und ist kostenlos :-)http://www.vstplanet.com/News/2014/Pitchproof-updated-to-v1.1-free-VST-and-AU-for-Mac-and-PC.htm Download:http://aegeanmusic.com/pitchproof-specs
@musicanderson Die von Dir genannten Tools dienen der Korrektur der Tonhöhe. PPG Phonem macht etwas gänzlich anderes. Es erzeugt künstliche Sprache, bzw. Gesang.
Mir ist es schleierhaft, warum Wavemapper und besser noch der Wavegenerator (beide für IOS) so ein Schattendasein führen. Für mich gehören sie vom Sound, von der GUI und von der internen Logik her zu den absoluten TOP-Synthies für IOS/Mac. Eigentlich braucht man dazu ev. noch Moog15 und ARP Odysey.
Ich hab mir geschworen 10 Jahre keinen HW-Synth zu kaufen (jetzt noch 7J), Das hat es mir erlaubt, alle IOS-Synthi-Apps zu kaufen ohne lang abzuwägen. Doch bis auf die og sind (fast) alle wieder gelöscht (iPad 128GB)..
Hallo Leute, wollte mal fragen, ob es ein vergleichbares VST gibt,
oder in naher Zukunft etwas vergleichbares auf den Markt kommt ?
Der Phonem klingt nämlich in meinen Ohren zu digital.
Das geht doch bestimmt besser :)
Höre grad den AquesTone2 und Alter/Ego (free)
die mich aber nicht überzeugen.
@Coin Nimm ein Micro und sprich rein. Dann hast du was besseres. Ich finde deine Bemerkung ziemlich borniert. Was soll denn deiner Meinung nach „besser“ gehen ?
Das sind immer so Kommentare, bei denen man vermutet, das wenig Sachverstand dahinter steckt.
Aber wenn ich mich irre und du der Soundprofi schlechthin bist, klär uns doch auf und beschreibe mal, was dir beim Fenom fehlt.
Denke, viel mehr kann man einfach nicht erwarten.Die menschliche Stimme ist bei weitem der individuellste Klang, den wir kennen. Dann das Problem der verschiedensten Artikulationsformen bedingt durch Hunderte von Sprachen und Dialekten. Was wir heutzutage noch bei Physical Modelling von Gitarre oder Klavier (zu recht) kritisieren, trifft natürlich in noch stärkerem Maße auf das Modelling von menschlicher Sprache und menschlichen Stimmen zu. Bin da auch beim Isaac Asmotiv dahingehen, dass man für den Fall, dass es wirklich menschlich klingen soll, schlichtweg ein Mikro benutzt. Und für schlechte Sänger gibbet immer noch melodyne und Co.
Guter Testberciht – danke Gerhardt! :)
Ich würde die hier genannten 119 € für Phonem sofort bezahlen, wenn ich eine Möglichkeit zum Kauf finden würde. Auf Wolfgang Palms Seite steht nur der Vermerk, das Phonem derzeit nicht zum Kauf angeboten wird.
Hat vielleicht jemand einen Tipp für mich, wo man dieses geniale Tool (legal) erwerben könnte?