

Zeitenwende: Künstliche Intelligenz in der Musikproduktion

Daniel Knoll und Markus Wegmann von Sounddub sind Experten für Künstliche Intelligenz in der Musikproduktion. Beide sind schon lange im Musikbusiness unterwegs und betreiben heute ein Dolby Atmos-Studio in der Nähe der brandenburgischen Stadt Jüterbog. Daniel entwickelt außerdem KI-basierte Software. Kennengelernt habe ich die beiden, als ich kürzlich von Markus sein Hohner Clavinet D6 gekauft habe. Es brummte vernehmlich: „Kein Problem, sicher eine Abschirmungssache, Daniel kriegt das hin“, meinte Markus. Und so fuhren wir ein paar Tage später zusammen zum Studio, das in einer ehemaligen DDR-Diskothek untergebracht ist.
Inhaltsverzeichnis
- KI. Künstliche Intelligenz in der Musikproduktion
- Zur Person Daniel Knoll
- Programmieren, um die Musik zu finanzieren
- KI und Musik: Wie ein Song in seine Einzelteile zerlegt wird
- Zur Person Markus Wegmann
- Die Sounddub-Software: Ein Traum für Trailer-Produzenten
- Sounddub: Leider nicht im Musikgeschäft erhältlich
- Restaurierung von Musik mit Künstlicher Intelligenz
- Wo liegt der Unterschied zu izotope RX und Co?
- Künstliche Intelligenz sortiert Musik nach Emotionen
- Wie die Sounddub-Software in der Praxis funktioniert
- Sounddub: Michael Jackson fest im Blick
- Soundzerlegung und Dolby Atmos-Bearbeitung
- Der Traum: Callas und Karajan in 3D Audio
- Ohne Latenz von Jüterbog nach Innsbruck
- Dolby Atmos-Studio: Ein bisschen Wahnsinn gehört dazu
- Künstliche Intelligenz und die Umwälzung in der Musikproduktion
- Künstliche Intelligenz in der Musikproduktion: Die Kneifzange für den Musiker?
KI. Künstliche Intelligenz in der Musikproduktion
Das Gebäude hat Daniel komplett selbst saniert – inklusive Strom, Heizung und Wasser. Das Clavinet klang nun ganz wunderbar (und wird hier demnächst in einer Velvet Box ausführlich gewürdigt). Ich war aber auch komplett umgehauen von dem Sounderlebnis Dolby Atmos. Keine Spur mehr von der manchmal etwas plakativen Aufdringlichkeit des früheren Surroundsounds. Atmos lässt einen ganz natürlich in die Musik eintauchen. Mit einer phantastischen Räumlichkeit und einem unglaublich plastischen Klangerlebnis. Fast beiläufig führte Daniel dann eine Software vor, die den Song We are family von Sister Sledge in seine einzelnen Spuren zerlegte: Drums, Bass, Stimme – als ob ein Mixing Engineer im Studio die einzelnen Kanalregler hochziehen würde. Meine Neugierde war geweckt und so trafen wir uns an einem schönen Sommerabend bei leckeren griechischen Vorspeisen (die Fischrogencreme!) im Terzo Mondo nahe des Berliner Savignyplatzes für ein Interview. Dass der Wirt auch mal bei Tangerine Dream Gitarre gespielt hat, war nur eine der Überraschungen des Abends. Und so führten wir bis in die Nacht ein sehr interessantes Gespräch, das den Bogen von Daniels Separierungs-Software über eine hochkomplexe Anwendung, die Musik in feinsten Abstufungen nach ihrem emotionalen Gehalt sortiert, bis zur aktuellen Umwälzung der Musikbranche durch Künstliche Intelligenz spannte.
Zur Person Daniel Knoll

Daniel Knoll (Foto: Costello)
Daniel Knoll ist bei Sounddub der Software-Tüftler. Geboren 1972 in Fürstenfeldbruck, mit vier nach Berlin gekommen, wo er zur Schule gegangen und Elektrotechnik studiert hat. Daniel entwickelt Software und hat mehrere Firmen gegründet, deren Verkauf ihm eine gewisse Unabhängigkeit beschert hat. Seine Liebe galt immer der Musik: Er hat lange in Studios gearbeitet, in der Produktion und im Mastering-Bereich. Markus hat er vor 25 Jahren kennengelernt in einem Studio am Berliner Kurfürstendamm, wo Daniel fürs Mastering und Markus für die Werbeproduktion zuständig war. Daniel ist überzeugt, dass durch Künstliche Intelligenz in ganz vielen Bereichen der Musikproduktion inzwischen der Zug buchstäblich abgefahren ist. (Foto: Costello)
Programmieren, um die Musik zu finanzieren
Costello
Daniel und Markus, ihr betreibt ein Dolby Atmos Studio. Und du Daniel programmierst nebenbei aber auch noch Software. Wie kam das eigentlich?
Daniel
Ich war ursprünglich mal Programmierer und habe sowohl eine Programmier-Historie, als auch eine Musik-Historie. Das ist eine ganz spannende Kombination. Und ich habe eigentlich immer programmiert, um Geld zu verdienen, war aber immer begeistert von der Musik. Ich habe viel im Studio gearbeitet, viel Produktion gemacht. Und die Programmierung hat mir immer die Miete bezahlt, wenn es denn dann mal nötig war. Und das war es öfter mal.
Costello
Was ich da neulich in eurem Studio gehört habe, hat mich ziemlich umgehauen: Ein bekannter Song wird buchstäblich in die Einzelteile zerlegt. Wie funktioniert das?
Daniel
Diese Software und das, was du gesehen und gehört hast, das ist eigentlich ein Abfallprodukt eines anderen hochspannenden Produkts. Darüber können wir vielleicht später noch sprechen. Das ist eine KI-basierte Zerlegung. Also ein trainiertes System, was nichts anderes macht, als bestimmte Teile in der Musik zu identifizieren. Zum Beispiel Schlagzeug oder Stimme oder Gitarre oder was auch immer, worauf man es halt trainiert hat. Und diese Teile dann physikalisch herauszurechnen aus dem Titel und sie als Einzelspuren auszugeben.
Costello
Das geht über die bekannte Karaoke-Funktion weit hinaus.
Daniel
Genau. Der Unterschied ist, dass diese alten Verfahren immer verlustbehaftet sind. Das heißt, du hast zwar in irgendeiner Form die Stimme so halbwegs rausbekommen aus der Musik, etwa beim Karaoke. Aber es war halt schon so, dass entweder die Stimme nicht ganz weg war und wenn doch, dann ging das zu Lasten des Backgrounds. Man hat es früher mit EQs gemacht, mit Phasenauslöschung und solchen Sachen. Aber das führt halt zu Aliasing- Effekten. Das klingt einfach nicht. Und das ist der Unterschied zur KI, weil die Künstliche Intelligenz rechnet das tatsächlich physikalisch aus der Musik raus.
KI und Musik: Wie ein Song in seine Einzelteile zerlegt wird
Costello
Das heißt, du kommst nicht einfach von den Frequenzen. Von der Spektralanalyse. Oder von den Transienten?
Daniel
Diese Dinge gehen da natürlich alle mit rein. Also im Endeffekt funktioniert das physikalische Separieren der Tracks natürlich auf der Basis einer FFT-Analyse und gegenphasigem Auslöschen. Das ist quasi das mechanische Prinzip, wie das rausgerechnet wird. Aber die Frage ist: Kann die Software identifizieren, was sie da rausrechnet? Und macht sie das so trennscharf, dass eben keine Aliasing-Effekte entstehen oder dass du irgendwas hast, was du eben nicht hören willst. Und das ist die Kunst.
Costello
Kurz zur Erklärung: FFT steht für Fast Fourier Transformation, dabei wird ein Signal in einzelne Spektralkomponenten zerlegt und dadurch erhält man Aufschluss über seine Zusammensetzung. Aber ich frage mich natürlich, wo liegen die Grenzen? Also wenn zum Beispiel eine Stimme mit sehr viel Hall versehen ist.
Daniel
Solange es zum Beispiel die eindeutige Charakteristik einer Stimme hat, gibt es da wenig Grenzen. Grenzen gibt es aber: und zwar bei sehr ähnlichen Klängen. Also z. B. bei Saxophon und Stimme. Das war auch schon beim Rundfunk früher immer ein Thema. Die liegen einfach so eng beieinander, dass man da, wenn das jetzt in Kombination vorkommt – was in Titeln selten der Fall ist – Schwierigkeiten bekommt. Da sind dann auch einfach mechanische Grenzen gesetzt.
Das Prinzip hören wir uns am Beispiel von Robbie Williams Interpretation des Brecht/Weill-Songs Mack the Knife einmal an. Zunächst die Originalfassung:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Und so klingt der Song, wenn er mit der Sounddub-Software in seine Einzelteile zerlegt wird. Im ersten Beispiel wird die Stimme herausgerechnet, wie man es zum Beispiel für Karaoke benötigt.
Die nächsten Versionen werden nun instrumental ausgedünnt.
Und zum Schluss Robbie Williams Stimme solo. Ich habe die ersten Sekunden weggeschnitten, damit der Gesang unmittelbar einsetzt. Hier und da sind noch kleine Artefakte und Nebengeräusche zu hören, aber Daniels Software hebt sich qualitativ deutlich von den Ergebnissen einer Stem-Extraktion ab, wie sie etwa LaLa.AI bietet.
Zur Person Markus Wegmann

Markus Wegmann (Foto: Costello)
Markus Wegmann ist ein alter Rundfunkhase und mit seiner markanten Stimme als Station Voice gefragt. Geboren 1962 im friesischen Varel, kommt er bald nach Kiel, wo er für den Privatsender R.SH die Soundelemente produziert. Er arbeitet sich schnell in die Digitaltechnik ein. 1994 geht es nach Berlin, wo er zunächst hilft, BB Radio aufzubauen, später macht er den Sound für die Sabine Christiansen Talkshow. Danach komponiert und produziert er die Filmmusik für 250 große Dokumentarfilme der 360 Grad GEO Reportage (ARTE). Heute weiß er: Jingles, Musikbetten und andere Funktionsmusiken bringen kaum mehr Tantiemen ein. Deshalb wollen er und Daniel mit Künstlicher Intelligenz in der Musik vor die Welle kommen.
Die Sounddub-Software: Ein Traum für Trailer-Produzenten
Costello
Jetzt frage ich mal den Markus: Rapper wie – ich sage mal – die Beastie Boys hätten sich bestimmt wahnsinnig gefreut, wenn sie dieses Tool zur Verfügung gehabt hätten. Und sie bei ihrem Album Pauls Boutique, das eine Sampling-Orgie vom Feinsten ist, aus einer alten Motown Platte an jeder beliebigen Stelle den Groove hätten rausziehen können.
Markus
Ja klar! Ich habe vor 30 Jahren im Privatfunk angefangen, Radio Schleswig Holstein, Jingles produziert für viele Radiosender nachher bundesweit, europaweit, in Holland viel, in Amerika viel. Wenn ich damals diese Möglichkeiten gehabt hätte, da wäre ich natürlich durchgedreht. Das ist die Antwort auf all die Radio und TV und Filme betreffenden Fragen. Rausheben von Dingen, wieder hinzufügen, Kombinationen. Das ist natürlich ein Traum für jeden Radio-TV-Audio Producer. Wenn ich dieses Tool damals gehabt hätte, wäre ich woanders heute.
Costello
Man darf bei Trailern ja auch nie über den Gesang quatschen …
Markus
Genau! Wenn du gefühlt 1000 Jingles und Trailer produziert hast, wo es darauf kommt, einen Künstler, nehmen wir Peter Maffay, spannend darzustellen, um beispielsweise zu einem Konzertbesuch zu animieren. Du hast maximal 30 Sekunden. Dafür ist dieses Tool gigantisch. Bleiben wir mal bei Maffay: Und es war Sommer und Klick ab dem Moment ist seine Stimme weg.
Costello
Da konntest du früher eigentlich nur das Intro für verwenden.
Markus
Ja, ja, genau! Und jetzt kannst du an jeder beliebigen Stelle einhaken und hast dann nur noch das Playback. Und weiter gesponnen, kannst du natürlich auch das Schlagzeug wegnehmen, also noch ganz andere Gimmicks einbauen.
Costello
Aber da glaube ich, gibt es auch ein rechtliches Problem?
Markus
Die Frage ist, darfst zum Beispiel im Radio oder Fernsehen das nutzen? Den Unterschied macht dabei: Solange es nicht auf Tonträger erscheint, ist das ja alles gar kein Problem. Ich hätte das in meiner Radio-, TV- und Filmzeit nutzen können. Denn ich bekam ja das Material von den Schallplattenfirmen zur Verfügung gestellt. Und die hätten das auch genossen, behaupte ich mal, wenn ich zu dem Zeitpunkt ein bisschen funky drauf gewesen wäre und hätte was gemischt. Wir durften ja auch in den Trailern verrückte Sachen machen. Da haben wir alles zusammengemischt – whatever. Du darfst es für die Erstverbreitung nutzen. Du darfst es nur nicht auf CD brennen – macht heute auch keiner mehr – also sozusagen auf einen Tonträger bannen und einfach zum Verkauf anbieten. Bei einer nachträglichen Veröffentlichung entstehen dann natürlich Rechtefragen, die geklärt werden müssen.
Sounddub: Leider nicht im Musikgeschäft erhältlich
Costello
Ich werde also eure Software eher nicht bei Thomann kaufen können?
Daniel
Diese Software wäre für B2C einerseits fantastisch, keine Frage! Ist da aber nicht das Richtige. Nee, das kann man natürlich nicht machen. Also sagen wir mal so im Falle Beastie Boys, was du vorhin angesprochen hast. Ich habe ja auch viel in der Musikproduktion und vor allem in der Schundpop-Produktion gearbeitet. In den 2000ern viel für die BMG gemacht und für die Sony gemacht und so was alles. Und da waren wir natürlich, wenn man das mal so sagen möchte, die Könige des Samples. Und man ist sich am Ende immer einig geworden. Also das heißt, wenn etwas kommerziell erfolgreich wird, einigt man sich mit der Zielplattenfirma und dann werden die Einnahmen geteilt und dann ist alles gut. Aber die Software, das, was wir da gemacht haben, damit lässt sich eher im B2B Bereich arbeiten. Das heißt: Fernsehsender, Radiosender oder überall da, wo halt Ton zum Bild gemacht wird, wo Trailer produziert werden, Werbung produziert wird. Man macht es und dann klärt man die Rechte. So funktioniert es eigentlich im praktischen Leben. Und gerade die Zerlegung des Mixes bietet unendliche Möglichkeiten. Etwa, das wieder neuusammenzumischen, um zum Beispiel sachtere oder leichtere Versionen von einem Titel herzustellen. Der ganze Bereich Remixing, wo einfach auch ein anderes Gefühl transportiert wird. Und das lässt man sich dann im Nachhinein freigeben. Also das hängt immer ein bisschen vom Produkt ab, aber das ist schon möglich.
Markus
Aber das ist ja gerade das Spannende. Für eine Station, beispielsweise jetzt R.SH ist das natürlich möglich, denn die haben alle Rechte daran in der Versendung. Das heißt, für einen Beitrag können wir die ganzen Gimmicks nutzen. Eben, wie Daniel es beschrieben hat, dieses B2B, da geht alles. Die Weiterverwertung auf Tonträger in welcher Form auch immer – da würde dann nachgefragt werden. Da ist bei uns eben auch Watermarking das Stichwort, ohne da jetzt zu tief einzusteigen. Das ist aber alles machbar. Die jeweiligen Anteile werden von uns automatisch aufgeteilt. Insofern ist es für Radio und Fernsehsender und auch Filmproduzenten hochinteressant, so sie eben Inhaber der Rechte sind. Dann können wir wirklich, sagen wir mal, gefahrlos loslegen.
Daniel
Gut, aber ich meine, wenn man sich jetzt als Nebennutzung für seine Geburtstagsparty eine Karaoke-Version von einem beliebten Titel macht, dann wird das wohl keinen tangieren.

Sollte ein schiefer Ton den Live-Mitschnitt trüben, lässt sich mit der Separierungssoftware noch etwas retten. Beim Peter Gabriel Konzert in der Berliner Waldbühne wäre das allerdings nicht notwendig gewesen. (Foto: Costello)
Restaurierung von Musik mit Künstlicher Intelligenz
Costello
Eure Software ist natürlich auch super geeignet für den gesamten Bereich Audiorestaurierung, könnte ich mir denken.
Daniel
Ganz genau. Das kann einmal Musik sein, es können aber auch EB-Aufnahmen sein, wo man Störgeräusche drauf hat. Da ist genau im entscheidenden Moment, wo Robert Redford das Interview gegeben hat, das Mofa durchs Bild gefahren ist. Da kann man eben die Stimme isolieren und dann ohne Mofa das wieder zusammenmischen, so dass das dann eben besser geht. Das ist ein bisschen was anderes als eine reine Rauschunterdrückung oder ähnliches. Als Beispiel haben wir hier eine Soundrestaurieung, die wir für eine ARTE-Doku gemacht haben. Der Bootsmotor übertönt die Stimmen. Im ersten Schritt haben wir das Motorengeräusch entfernt und die Stimmen freigestellt. Damit die Aufnahme aber nicht steril wirkt – die Szene spielt ja nun mal auf einem Boot – haben wir das Motorengeräusch wieder leicht dazugemischt.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Oder nehmen wir Liveaufnahmen. Also ich meine, live ist halt live und da geht halt auch was schief oder der Sänger hat sich versungen. Sensationelles Konzert, aber leider Titel Nummer sieben, was die Hymne ist, da hat er sich versungen, den dann rauszunehmen und diese kleine Korrektur vorzunehmen. Du kannst die Aufnahme mit dieser Stimmung nicht noch mal machen. Das geht halt nicht. Dafür ist unsere Software sehr gut geeignet. Und diese Korrektur, wenn die Stimme frei steht, kannst du dann super mit Melodyne machen. Das ist ein wirklich geiles Produkt. Da sage ich nur Chapeau. Also dieses Tool ist wirklich großartig gemacht.

Künstliche Intelligenz in der Musik: Die Zerlegung des Audiomaterials mit der Sounddub-Software ermöglicht es u. a., bei einer misslungenen Live-Aufnahme, die Stimme zielgenau mit Melodyne zu korrigieren.
Wo liegt der Unterschied zu izotope RX und Co?
Costello
Nun tummeln sich auf dem Markt für Audiorestaurierung ja sehr viele Wettbewerber. Wie unterscheidet sich eure Software von aktuellen Produkten, die schon auf dem Markt sind, wie etwa izotope RX? Oder auch Lösungen wie Cedar DNS, Waves Clarity Vx Pro, Steinberg SpectraLayers und Zynaptiq Repair?

Der Markt für Software, mit der man Audio restaurieren kann, ist hart umkämpft. Ein bekanntes Produkt ist Izotope RX.
Daniel
Ja, das sind genau die Klassiker, die Magic Wands der Audio-Software. Ja, gut, die gibt es natürlich und die funktionieren auch. Das ist alles außer Frage. Aber das ist Generalisten-Software. Das muss man schon ganz klar sagen. Die müssen ein sehr breites Kunden-Klientel bedienen und die haben ein sehr breites Anwendungs-Spektrum. Das heißt, die müssen sowohl die Musik können, als auch die EB-Aufnahme und so weiter. Und wie man sich unschwer vorzustellen kann, löst das nicht Spezialisierte diese Aufgaben zwar auch ganz okay, hat aber eben auch starke Grenzen. Wenn man damit professionell arbeitet und das mache ich, dann merkt man auch bei sehr schnell. Also selbst bei den genannten Tools.
Costello
Restaurieren ist sehr aufwändig. Das ist ja immer noch eine sehr anspruchsvolle Aufgabe. Du kannst ein gutes Tool an der Hand haben, das ist das eine. Aber du brauchst ja im Prinzip auch Grundkenntnisse in Mathematik, in Physik. Ist eure Software für den Anwender ohne weitere Vorkenntnisse zu bedienen oder musst du dafür …
Daniel
… sozusagen Physiker sein? Nein. Also sagen wir mal so: Vom Benutzerinterface her musst du Physiker sein, weil es hat kein Benutzerinterface. Also das ist ja wie gesagt eine Anwendung – eigentlich ein Abfallprodukt – die rein auf dem Server läuft, weil wir das als Dienstleistung anbieten. Aber natürlich vom „was gebe ich rein, was kriege ich raus?“ musst du gar keine Kenntnisse haben. Das gibt dir einfach das raus, was du willst. Also wenn du sagst „Stimme“, dann liefert dir die Software die Stimme. Und dann gibt es ein Wavefile und das kannst du ja weiter verarbeiten als Nichtphysiker.

Mit künstlicher Intelligenz auf der Suche nach den emotionalen Parametern in der Musik: Markus Wegmann und Daniel Knoll in ihrem Dolby Atmos-Studio. (Foto: Costello)
Künstliche Intelligenz sortiert Musik nach Emotionen
Costello
Jetzt hast du wieder den Begriff „Abfallprodukt“ benutzt. Abfall von was denn?
Daniel
Es gibt eigentlich das große Ganze. Da arbeiten wir seit gut drei Jahren dran. Das ist eine KI-basierte Medien-Datenbank, die es vereinfachen soll, sich die richtige Musik für den Zweck, den ich verfolge, auszusuchen. Der Zweck könnte sein, die passende Musik für ein Video, einen Trailer, ein Video, einen Film zu finden. Und da geht es darum, dass die music emotions klassifiziert werden. Das heißt, man kann Musiken nach Emotion, nach Energie, nach Kraft und so weiter und so fort suchen – und zwar buchstäblich mit dem Schieberegler. Also ohne Schlagworte, ohne Text und so was alles, sondern einfach nur mit Schiebereglern. Das ist technisch wahnsinnig aufwendig, weil wir es hier mit menschlichen Gefühlen zu tun haben, mit Emotionen. Aber damit man das technisch darstellen kann, braucht man da verschiedene Untervorbereitungsschritte der Musikanalyse. Dazu gehört unter anderem das Zerlegen von Musik, weil dann zum Beispiel die Dynamik, die Drums usw. erst mal rausisoliert werden müssen. Damit man sie separat von dem Gesamtkunstwerk betrachten kann. Deswegen sage ich immer Abfallprodukt, weil das eine der ersten Stufen dieser Analyse-Software ist, die wir da entwickelt haben.
Costello
Habt ihr euch dabei auch externen Rat geholt?
Daniel
Ja, denn da steckt natürlich ein ganz erheblicher Anteil Psychologie dahinter. Wir haben zum Beispiel mit der Uni Potsdam zusammengearbeitet, der Psychologischen Fakultät. Und da ging es darum, wie Zielgruppen bestimmte Musiken empfinden oder welche Emotionen in ihnen ausgelöst werden, wenn Musiken abgespielt werden. Also das sage ich jetzt mal vereinfacht mit einer bestimmten Zielgruppen-Analyse. Weil es bei dem System natürlich auch darum ging, das jetzt nicht nur für den europäischen Raum zu machen, sondern auch für Nordamerika. Oder auch – und da wird es richtig kompliziert für den Europäer – für den asiatischen Raum, afrikanischen Raum oder arabischen Raum.
Costello
Emotionen sind nicht überall auf der Welt dasselbe: Was als fröhliche, lebhafte oder sentimentale Musik empfunden wird.
Daniel
Nein, überhaupt nicht. Gar nicht. Aber das Ziel der Anwendung war es, quasi ein universelles Werkzeug zu haben, wo ich Musik vorne reinkippe und hinten kommt eine ordentliche Klassifizierung raus, die weltweit gültig ist. Wenn ich sage, ich möchte eine fröhliche Musik haben, dass da eine fröhliche Musik herauskommt. Und zwar in Indisch, in Arabisch und in Deutsch. Wenn ich den Schieberegler auf sehr fröhlich schiebe. Und das ist die Kunst. Und deswegen muss ich sehr viele analytische Verfahren über die Musik laufen lassen, um die Künstliche Intelligenz zu trainieren. Und dazu gehört halt auch, nicht nur die Musik im Ganzen zu betrachten, sondern auch die ganzen einzelnen Elemente, auch in der Stimme, welche Emotionen da mitschwingen, in dem Saxophon, was da sein Solo spielt, in der Gitarre.
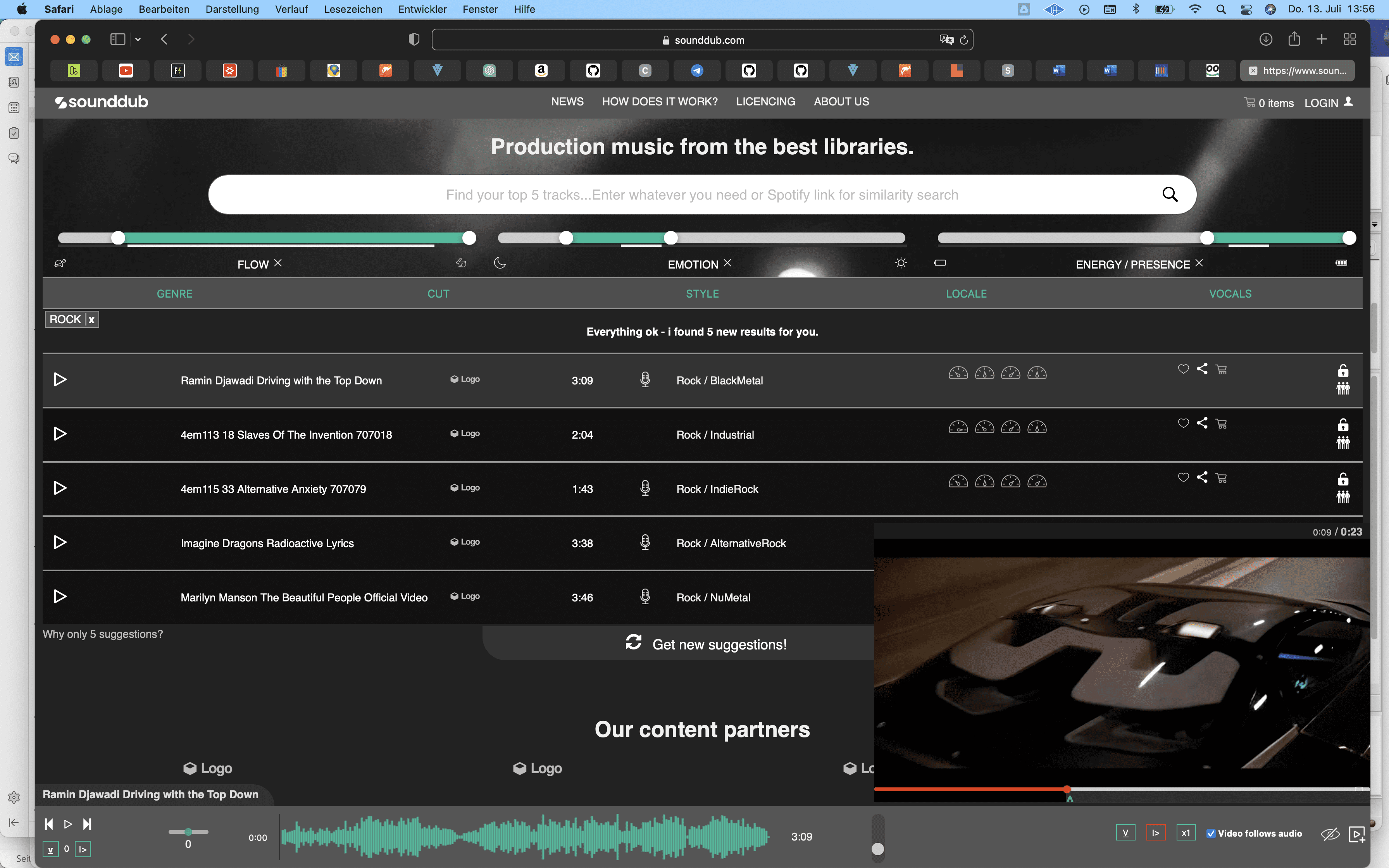
Die Benutzeroberfläche der Sounddub Mediabase, bei der mit Künstlicher Intelligenz Musik nach Emotionen analysiert und sortiert werden kann
Wie die Sounddub-Software in der Praxis funktioniert
Costello
Das ist ein komplexes System! Magst du mal versuchen, es in einfachen Worten zu beschreiben, wie die Künstliche Intelligenz die Musik analysiert, wie es in der Praxis funktioniert?
Daniel
Sehr gerne! Unser sounddub mediabase System funktioniert eigentlich ganz einfach. Du lädst bestehende Musiktitel in das System und dann passiert Folgendes: Mehrere KIs zerlegen die Musik und klassifizieren sie. Im Anschluss werden die Titel mit einer großen Zahl von menschlich verständlichen Parametern versehen.
Wichtig ist die nachgeschaltete Bias-Matrix. Denn die stellt den interkulturellen und Genre-übergreifenden Zusammenhang her. Worüber wir gerade gesprochen haben: dass du als Ergebnis gleich positive Emotionen in unterschiedlichen Ethnien und Genres bekommst. Das Besondere dabei ist, dass die sounddub engine nicht nur „Tags“ an die Titel heftet – ich sage jetzt mal „heroisch“, „düster“, „fröhlich“,“Rock“, „Jazz“, „Afrikanisch“ oder auch „Mit weiblichen Vocals“, sondern das Ganze auch quantitativ fein granuliert bewertet.

Mit diesen 3 Schiebereglern können jeweils Bereiche in den 3 Kategorien bestimmt werden. Danach richtet sich die vorgeschlagene Musikauswahl. Der schmale Strich unter den Reglern zeigt den Bereich, in dem sich die Top 5 Auswahl bewegt.
Costello
Es geht also über die Schublade „Ballade mit melancholischem Charakter“ weit hinaus?
Daniel
Richtig! Wir messen auch, wie sehr eine Eigenschaft in der Musik vorhanden ist. Also zum Beispiel „extrem melancholisch“. Gleichzeitig wird die Musik noch mit einem Fingerprint und einem Watermark versehen, damit man sie im fertigen Werk identifizieren kann. Und dann werden zusätzlich noch die markanten Stellen – z. B. der Chorus – herausgetrennt und in unterschiedlichen Versionen gespeichert.
Sinn der ganzen Übung ist es, Nutzern ein simpel zu bedienendes menschennahes Interface bzw. Produktionswerkzeug bereitzustellen, um die perfekte Musik für ein Projekt in kürzester Zeit zu finden. Das geht aber nur dann, wenn die Maschine den Menschen versteht und nicht umgekehrt. Der Nutzer muss sich nur die Frage stellen: Was oder welches Gefühl möchte ich beim Zuschauer oder Zuhörer auslösen?
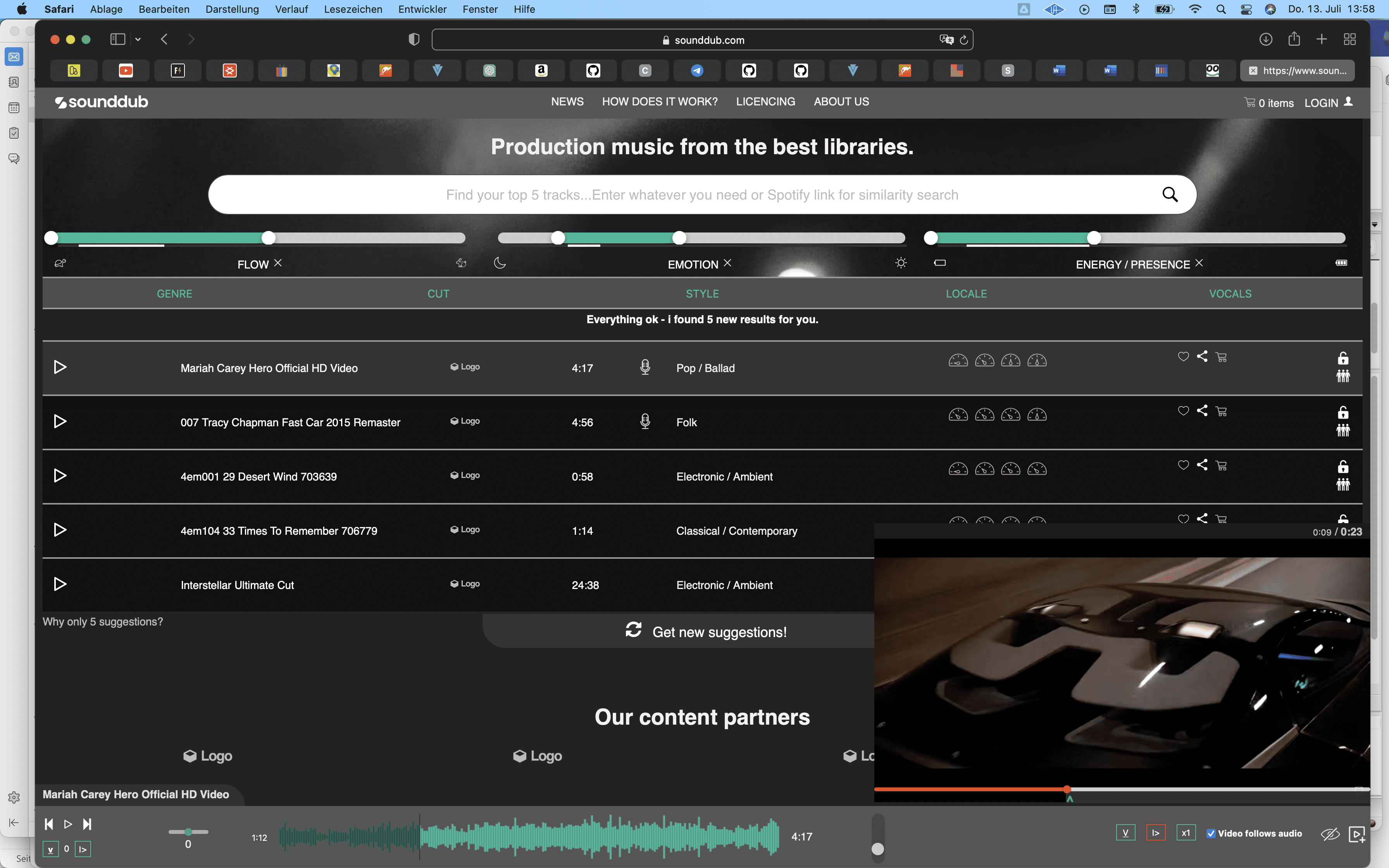
Mit den grünen Parametern kann die Auswahl bei der Sounddub Mediabase weiter verfeinert werden: Genre, Style = unplugged / only natural instruments, locale = kultureller / geografischer Hintergrund, vocals = female / male / none
Sounddub: Michael Jackson fest im Blick
Costello
Mögt ihr mal erzählen, mit wem seid ihr da in Kontakt? Dürft ihr da ein paar Namen nennen?
Daniel
Ja, also gut, wir haben natürlich jetzt mit vielen Majors gesprochen. Zunächst mal mit Blick auf die Zweckmusiken, weil wir gesagt haben, okay, dann gebt mal eure Zweckmusiken her, wir kategorisieren die ein und dann habt ihr die in einer Version.
Costello
Aber Funktionsmusiken sind jetzt nicht das Gleiche wie der Gesamtkatalog.
Daniel
Uns geht es natürlich vor allem auch um die großen Kataloge. Also das heißt, uns geht es um Michael Jackson, um die Beatles und so weiter. Wir wollten der Anbieter sein, wo wir dann auch sagen: Okay, dann haben wir mal die anderen Versionen davon und wir kategorisieren die ein und stellen die halt professionellen Produktionen zur Verfügung. Was du nicht vergessen darfst, ist natürlich, dass professionelle Produktionen Zugriff auf sechs, sieben Millionen Titel haben. Und für den Redakteur, der im Endeffekt den Beitrag macht, der hat halt auch sechs, sieben Millionen Titel. Und damit der den Überblick behält, den richtigen findet und die richtige Version von dem richtigen. Da ist unsere Software eine große Hilfe. Es hilft durchaus, wenn du das innerhalb von einer Minute machen kannst. Bei RTL oder bei Universal gibt es einen, der hat das auf seinem Server. Und dann findet er die gewünschte Emotion und auch die richtige.
Und das gab es halt so noch nicht. Weil normalerweise läuft so eine Datenbank in irgendeiner Form taggesteuert. Das heißt, da sitzt ein fleißiger Redakteur und sagt da „traurig“ oder irgendwelche anderen kategorisierenden Worte. Er hat aber ein subjektives Empfinden zu dem Titel, was das Ergebnis natürlich total unobjektiv macht. Oder da hat jemand viel Fleißarbeit reingesteckt.
Costello
Mich erinnert es aber auch ein bisschen an Spotify. Wenn man da einen Song anwählt und es kommen danach ähnliche Lieder.
Daniel
Das macht Spotify. Die setzen KI ein, um die Playlisten zu erzeugen zum Beispiel. Das ist mal besser, mal schlechter. Genau richtig. Aber die machen was ähnliches. Auch YouTube macht das, wenn du Videos schaust, dass du dann ähnliche Vorschläge kriegst. Das ist alles schön und gut. Aber was du nicht hast, ist, dass du wirklich einen Bereich von Emotionen einschränkst und sagst: Okay, das sind jetzt meine Vorschläge und die gefallen mir nicht. Ich möchte fünf neue oder ich sage, der Vorschlag gefällt mir, noch mal Ergebnisse ähnlich wie der. Entsprechend macht sounddub immer 5 Vorschläge, die immer wieder intuitiv verfeinert werden können, bis man seine Top 5 gefunden hat. Und das im Produktionsbereich gibt es halt einfach wirklich gar nicht. Und dass das halt auch funktioniert. Diese Anwendung ist gerade auch für die Film- und Videoproduktion sehr nützlich. Du kannst in unsere sounddub mediabase Videodateien problemlos einbinden und zwar ohne Upload und dann mit den Titeln synchronisieren. Das beschleunigt den Workflow natürlich immens.

Das sounddub mediabase-Interface mit geladenem und synchronisierten Video
Costello
Eure Anwendung von Künstlicher Intelligenz in der Musikanalyse ist sicher auch interessant für Streaming-Dienste, die immer vor der Frage stehen: Wie wird eine Musik in einem bestimmten Zielmarkt empfunden.
Daniel
Genau. Also tatsächlich ist es ja so, dass aufgrund der kulturellen Unterschiede gerade Netflix oder Amazon Prime, die halt viele Serien produzieren, eigene Scouts und Agenturen beschäftigen. Die sich nur darum kümmern, wie der musikalische kulturelle Kontext in dem jeweiligen Land ist. So, das müsstest du dann nicht mehr haben.
Costello
Das kann leicht nach hinten losgehen.
Daniel
Wo das Publikum dann sagt: Willst du mich verarschen jetzt, das meinen sie nicht ernst. Damit kannst du relevante kulturelle Probleme auslösen.
Costello
Wie läuft das bei euch in der Praxis ab?
Markus
Wenn ein Sender mit uns kooperieren möchte, dann kommen wir vorbei, dann kriegt jeder Redakteur da seine Desktop-Version und dann kann er das, was Daniel gerade erzählt hat, einfach nutzen. Ich komme noch aus einer anderen Generation – noch mit CDs. Lass uns mal weiterdenken. Ich habe ja noch auf Senkeln – also Tonbändern – gelernt. Und ich war dann irgendwann Musikberater. Und diese Funktion hat sich mit unserer Software tatsächlich erledigt, weil jeder Redakteur wird jetzt zum Musikberater. Der schafft das einfach schlicht und ergreifend besser als jeder Musikberater, weil die Software natürlich viel tiefer geht.
Daniel
Das alles bieten wir natürlich auch als Dienstleistung an. Also das heißt abseits von dieser Plattform, die ja so wunderbar und magisch ist, bieten wir natürlich die ganz normale Dienstleistung an. Das heißt, die ganze Audio-Restauration, das professionelle Zerlegen und eben dann remixen und aufarbeiten, Remixe in Dolby Atmos von Dingen, die man gar nicht remixen kann.

Daniel Knoll in seinem Element: Bei der Arbeit im Dolby Atmos-Studio (Foto: Costello)
Soundzerlegung und Dolby Atmos-Bearbeitung
Costello
Welche Rolle spielt eure Software denn in eurem Dolby Atmos-Studio?
Daniel
Na ja, das ist ja natürlich ganz entscheidend, wenn wir mal an alte Aufnahmen denken, früher Monoaufnahmen, dann Stereoaufnahmen in den 60er-, 70er-Jahren. Das können wir remixen, weil wir natürlich die komplette Aufnahme zerlegen können.
Costello
Auch so eine olle Karajan-Aufnahme?
Markus
Olle Karajan-Aufnahme! Ich muss schon bitten. Aber auf jeden Fall ja, natürlich, klar, wir können da eingreifen in den Mix und Violinen, Bässe, Holzbläser, Blech, Schlagwerk und ggf. Gesang separieren und danach räumlich mit dem Dolby Atmos-Verfahren korrekt zuordnen. Oder wenn wir jetzt mal in die U-Musik gehen, dann wir nehmen die Beatles. Da haben wir halt eine Mono- oder Stereoaufnahme, wenn es gut lief oder eine Vierspur. Aber wir können halt reingehen in die Aufnahme und können mit modernen Methoden das halt in Einzelspuren zerlegen und das neu mischen und dann auch in einem angenehmen Atmos Mix herstellen.
Costello
Habt ihr denn sowas im klassischen Bereich schon mal ausprobiert?
Daniel
Ausprobiert ja, professionell gemacht in Form einer Platte noch nicht.

Theoretisch ließe sich die Sounddub-Software auch für klassische Musik verwenden. Hier das DSO in der Berliner Philharmonie. (Foto: Costello)
Costello
Ich stelle mir das schwieriger vor. Popmusik ist ja meist sehr plakativ. Drums, Bass, E-Piano, Gitarre, Gesang, Aber Oboen und Klarinetten, Bratschen und Celli …
Daniel
Ja, das ist noch mal was anderes. Aber es hängt ja immer davon ab, wie man das System trainiert. Das können wir ja frei trainieren. Aber was man nicht glauben braucht ist, dass man sich da jede einzelne Violine rausholt. Die erste Violine, die holt man sich noch raus. Aber das hat Grenzen. Und die Gruppen kann man selbstverständlich separieren: die Holzbläser, die Blechbläser, die Streicher. Das kannst du trennen, weil das einfach eine gewisse unterscheidbare Charakteristik hat. Das ist ja auch kein Zauberhut, sondern das ist einfach Mathematik. Da hast du andere Probleme. Also entweder gibt es da Störungen drin, weil was schiefgelaufen ist, also gerade bei Live-Aufnahmen läuft gern was schief. Wir denken an die klassische Open Air Waldbühne, solche Themen. Da schreit halt einer mal rein. So was kriegst du natürlich ganz hervorragend gelöst. Ein Remix von einer klassischen Aufnahme ist auch eine wirklich kritische Angelegenheit, weil du klassisch nicht so mischst. Du mischst nicht die einzelnen Streicher, du mischst, wenn überhaupt, sektionsweise, du machst Stereoaufnahmen. Aber wenn wir jetzt sagen, wir wollen ins immersive Erlebnis, wo wir sagen, wir wollen ins Atmos-Erlebnis, also vielleicht im Orchester, oder vor dem Orchester stehen, dann hast du die Möglichkeit, das räumlich zu gestalten mit dieser Technologie. Weil du dann überhaupt noch gestalten kannst, was du in der Stereoaufnahme nicht kannst. Da darfst du ja auch nicht mit Phasen rumspielen, aber du kannst dann zumindest den Raum herstellen.
Costello
Klingt spannend …

Maria Callas im Dolby Atmos-Sound? Das Sounddub-Team hätte nichts dagegen.
Der Traum: Callas und Karajan in 3D Audio
Daniel
Also unsere Idee ist jetzt auch wirklich, ich bin mal provokant, die Deutsche Grammophon anzusprechen. Stichwort alte Maria Callas Aufnahmen, Mono natürlich, Furtwängler, Karajan. Wir sind in der Lage, daraus 3D Audio zu machen. Und das Erlebnis, wir haben haben es ja ausprobiert, ist gigantisch. Und das ist etwas, wo wir zum Beispiel natürlich offensiv noch rangehen. Da würden wir uns freuen, wenn die entsprechenden Labels mal auf uns zukommen würden, ich sage es jetzt einfach mal so. Wir sind in der Lage, da wirklich ein völlig neues Erlebnis zu schaffen.
Markus
Das heißt, Mono wird nicht nur Stereo, sondern wird Raum. Und das im Klassikbereich ist natürlich genial.
Daniel
Mit einer Aufnahme, die 60 Jahre alt ist, da wäre ich selber persönlich gespannt. Wir bräuchten die Rechte dafür. Das heißt, da müsste die Grammophon mit ihren Rechteinhabern auf uns zukommen und sagen Kinder, macht das bitte mal.
Costello
Verdient ihr eigentlich auch Geld mit eurem Tool?
Daniel
Da müssen wir unterscheiden: Die Zerlegung ist eine reine Dienstleistung, die Audio-Restauration ist eine Dienstleistung. Die Katalogisierung mit unserer music emotions-Software ist Lizenzgeschäft.
Costello
Da kommen ja auch ständig neue Sachen dazu und die müssen …
Daniel
Genau, die müssen dann auch einsortiert werden. Also das wird dann ja nicht jedes Mal wieder ein komplett anderes Produkt. Deshalb wird die Plattform einfach lizenziert für so und so viele Plätze und dann ist es gut. Das läuft dann auf jährlicher Basis und dann ist es okay. Zufrieden ich bin.

Auch wenn Markus Wegmann jetzt in Innsbruck lebt, kann er mit Daniel Knoll weiter zusammenarbeiten – latenzfrei. (Foto: Costello)
Ohne Latenz von Jüterbog nach Innsbruck
Costello
Markus, du packst gerade deine Koffer in Potsdam zusammen und ziehst nach Innsbruck. Was bedeutet das für euer Studio und eure Zusammenarbeit?
Markus
Ich komme in Innsbruck sehr fürstlich unter, obwohl Innsbruck preislich ähnlich liegt wie zum Beispiel München. Ich gehe im Prinzip an einen Urlaubsort, den ich genieße. Aber für unsere Zusammenarbeit ist es prinzipiell völlig wurscht, wo ich bin.
Daniel
Wir haben eine 16-Kanal Realtime-Verbindung ohne Latenz. Das heißt, wenn wir einen Atmos Mix in Jüterbog machen, dann können wir den in Atmos in Innsbruck abhören. Wir haben da einen Abhörraum ohne Latenz und zwar mit Rückkopplung. Also das heißt, wir können hin und zurück. Und dann kann der Markus seinen Senf auch dazugeben.
Markus
Und dann hast du Atmos vor Ort und kannst den Regler ziehen und es passiert in Laufzeit, der Laie sagt in Echtzeit, aber zur Laufzeit passiert es da, ohne Latenz. Viele Regisseure wissen das noch gar nicht. Also in Österreich wird zum Teil auch nur die Action-Elite in Atmos produziert. Mit unserer Technologie ist das eigentlich überall jetzt möglich und das ist auch gar nicht so aufwendig. Es ist mit Verlaub auch gar nicht mal so teuer, weil wenn du schon in 5.1, was die meisten machen, produzierst, dann kannst du das auch gleich in Atmos machen. Das Entscheidende ist nur die Abhörsituation. Und es gibt in Europa halt nicht so viele.
Costello
Habt ihr von Dolby eine Zertifizierung?
Daniel
Wir sind im Dolby Katalog und alles eingemessen auf Dolby. Das Wort zertifizieren benutzt Dolby nicht mehr. Der offizielle Sprachgebrauch der Dolby AG ist nicht zertifiziert, sondern akzeptiert.

Ein Blick in das Dolby Atmos-Studio von Daniel Knoll und Markus Wegmann. (Foto: Costello)
Dolby Atmos-Studio: Ein bisschen Wahnsinn gehört dazu
Markus
Wir denken auch drüber nach, wirklich auch so für Projekte unsere Anlagen zur Verfügung zu stellen. Letztendlich geht es ja um die Abhörsituation und die Studios sind eben gezählt, weil der Aufwand, den wir da in Jüterbog betrieben haben, der ist erheblich. Wir sitzen da in einer ehemaligen Diskothek. Ich will es gar nicht aufzählen. Du hast es ja gesehen, die Quadratmeter, du brauchst Raum, du brauchst Laufzeit. Das kannst du nicht irgendwo hinstellen. Allein da scheitert es schon dran. Die Technik zum Teil. Das grenzt schon an Beschaffungskriminalität. All die Geräte. Es ist insgesamt ein unglaublicher – auch finanzieller – Aufwand.
Daniel
Und ein logistischer Aufwand, so ein Dolby Atmos Studio zu realisieren. Wir können es nur deswegen machen, weil wir krank im Kopf sind. Ja, das ist wahr. Das muss auch sein. Nee, aber tatsächlich ist es so, ich meine, das ist alles vorfinanziert. Wir haben das einfach gemacht, weil wir das machen wollen und weil wir das selber mögen. Da ist ganz viel Leidenschaft in dem Projekt, auch in dem anderen Projekt steckt wahnsinnig viel Leidenschaft, weil das schon unglaublich spannend ist. Und wenn man Musik liebt, dann macht man solche Dinge. Und Markus geht jetzt nach Innsbruck, weil er sich das verdient hat. Und wir nutzen einfach den Standort Innsbruck, damit wir in Österreich halt auch einen Standort haben, was einfach gut ist. Und Innsbruck ist zentral und wir können dann halt einfach die Märkte bedienen. So einfach ist das.

In einigen Ecken des sounddub-Studios sieht es noch sehr nach musikalischem Handwerk und noch nicht nach KI aus (Foto: Costello)
Künstliche Intelligenz und die Umwälzung in der Musikproduktion
Costello
Sagt mal, weil ihr jetzt so in diesem Thema künstliche Intelligenz in der Musikproduktion drinsteckt. Also was ich mitbekomme, überschlagen sich die Dinge da wirklich in allen Bereichen, die mit KI zu tun haben. Manches ist auch ein bisschen gruselig, also trainierte Stimmen, die dann plötzlich wie David Bowie klingen, wie Beyoncé oder wie Eminem. Was ist eure Prognose, wo das hingeht?
Daniel
Tatsache ist, die künstliche Intelligenz in der Musikproduktion wird ganz viele Leute treffen. Also viel arbeitendes Volk, sag ich mal. Dazu zählen Sprecher, dazu zählen Musikkomponisten, weil der gesamte Bereich Funktionsmusik entfallen wird. Also alles, was da an Komponisten unterwegs ist, wird wegfallen. Das geht auch in den Bereich Filmmusik. Die Technologie ist jetzt bereits so weit. Im Wettstreit zwischen Microsoft und Meta bei der Stimmenemulation, also dem Nachbilden von realen Stimmen, da geht es mittlerweile nicht mehr darum, ob es geht, sondern darum, wie viel Sekunden Sprachsample sie brauchen von der Person, bis sie perfekt emuliert ist. Und da sind wir bei 20 Sekunden. Meta haben ihr Modell vom Markt genommen, weil sie sagen, okay, da geht jetzt eine relevante Gefahr davon aus. Weil das natürlich missbraucht werden kann für Deep Fake, für Manipulation, Kriminalität etc. Ja aber auch im Bereich der Musikkomposition: Google ist da Vorreiter mit Google MC. Seit Januar am Markt für Musikkomposition, die per KI passiert. Und da geht es ja nicht um Emulation, also das Nachbilden von Musik mit Hilfe von Künstlicher Intelligenz, sondern um Kreativität. Im Bildbereich haben wir Dali. Es ist vorbei. Der Zug ist abgefahren. Wir können das auch nicht mehr rückgängig machen. Man kann das versuchen, also die Verwertungsgesellschaften versuchen das gerade. Also auch die großen Labels versuchen das gerade. Wir hatten jetzt gerade Beispiele bei Sony, wo halt rein KI komponierte Mashups und Musiken rausgekommen sind, die in die Charts gehen.
Costello
So funktioniert Disruption.
Daniel
Nächstes Jahr ist das Thema durch. Meine Prognose. Wir haben noch zwölf Monate Zeit für den Musikbereich. Und dann ist es komplett anders. Also im professionellen Bereich. Alles, was damit Geld verdient, also professioneller Trailerbereich, Funktionsmusiken, Sprecher ist Geschichte.

Was sind die Konsequenzen der KI zum Beispiel für professionelle Sprecher? Da macht sich auch Markus Wegmann seine Gedanken. (Foto: Costello)
Costello
Markus, du schaust so entsetzt.
Markus
Entsetzt? Ja, weil mein Bier gerade alle ist. Genau weil es mich betreffen wird. Ich bin u. a. Station Voice bei einem nationalen TV-Anbieter, spreche Werbespots, Comedies und Hörbücher. Und genau aus diesem Grund sind wir gerade dabei, das ganze Thema für die Media- und Musikindustrie im Produktionsalltag nutzbar zu machen.
Costello
Wenn sie ein Sample von dir haben, können sie damit jeden Trailer von dir einsprechen lassen.
Daniel
Sie müssen den Text nur eintippen. Und die Emotion festlegen. Das ist es, was
diese Sprachmodelle können. Jetzt! Nicht irgendwann. Und deswegen ist es obsolet zu sagen, das fängt an mit der Low-Budget-Produktion bis Mid-Budget. Das dauert nicht lange, dann ist es High-Budget, die dann auch das benutzen. Es gibt auch gar keinen Grund mehr dafür, du kannst den beliebig lange einsetzen, der wird nicht heiser, der wird nicht krank und da kannst du alles ausprobieren. Und das ist auch eine – man darf das nicht alles verteufeln – das ist auch eine völlig neue Form der Kreativität, die sich da öffnet.
Costello
Aber Tom Cruise bekommt dann wenigstens Tantiemen, wenn ein Trailer mit seiner Stimme gesprochen wird.
Daniel
Die Frage ist, ob es dann später nicht auch einfach berühmte AI-Voices gibt, die überhaupt kein reales Vorbild haben. Die sie emulieren. Wo sie Mashups machen und sagen: Okay, ich möchte Robert De Niro gekreuzt mit Robert Redford. Das kannst du am Ende gar nicht mehr zuordnen. Du hast das Gefühl, du kennst es. Es ist irgendwie sehr vertraut. Aber ich sage ja, das ist eine völlig neue Form der Kreativität, die sich daraus ergibt. Man darf nicht immer nur sagen, da werden Leute arbeitslos. Das ist natürlich schlimm. Ich meine, tatsächlich gibt es ganz neue künstlerische Möglichkeiten, weil du musst auch das bedienen können.

Die Künstliche Intelligenz wird sich disruptiv in der Musikbranche auswirken. Trotzdem sieht Daniel Knoll auch Chancen. (Foto: Costello)
Künstliche Intelligenz in der Musikproduktion: Die Kneifzange für den Musiker?
Markus
Ich finde es spannend, dass Daniel das so positiv betrachtet. Also nicht immer die negative Seite der KI herauszustellen, die wird ja im Moment sehr hervorgehoben. Das ist auch unser Ansatz, gerade auch die Kreativität dahinter zu nutzen. Weil im Endeffekt muss es immer noch einen geben, der sagt: Ja, genau so will ich das, so soll der Videotrailer aussehen. Weißt du, da konzentriert sich der Mensch mal wieder auf das, was er eigentlich wirklich gut kann, nämlich Kreativität, Emotionen spüren, Emotionen vermitteln. Da ist Künstliche Intelligenz in der Musikproduktion ein Werkzeug, das ist eine bessere Kneifzange.
Costello
Bei euch ist das ein Schieberegler …
Daniel
Von links nach rechts. Genau so ist es. Aber irgendwer muss den Schieber schieben und muss sagen: So ist es gut. Genau so will ich es. Weil das war das, was ich versuchte auszudrücken. Ich habe es jetzt bloß leichter und es demokratisiert den Markt. Bei den Studios zum Beispiel: Früher Studiobesitzer zu sein, bedeutete eine Million Mark, das war halt so, sonst lief das Ding nicht. Heutzutage Laptop und das demokratisiert, mehr Leute können Musik machen und mehr Leute können kreativ sein, weil die Sachen erschwinglicher geworden sind. Und ich finde, das ist kein schlechter Aspekt. Und wenn KI mehr ermöglicht, zum Beispiel mit der Stimme von Tom Cruise, den singen zu lassen, dann ist das für Tiktok allemal in Ordnung. Und wenn ich das Jugendlichen und Kindern und auch Künstler*innen, um das jetzt Mal korrekt zu sagen, ermögliche, dadurch das zu demokratisieren und mehr Leuten Zugang zur Musik verschaffe, ist das doch gut. Und nicht jeder muss acht Jahre Klavierunterricht haben, damit er ein gutes Stück machen kann. Es kommt darauf an, dass er sagt, es ist gut. Und ob dann andere das auch gut finden, ist eine andere Sache. Aber ich habe eine Kneifzange, die ich als Mensch bedienen kann, die mich versteht und nicht, wo ich mich in die Welt der Maschine begeben muss und ihr erst mal erklären muss, was ich eigentlich von ihr will. Das ist der Vorteil von KI.
Costello
Lieber Daniel, lieber Markus – danke für das Gespräch.



Cooles Interview! Ich finde den Optimismus der Beiden super! Allerdings sehe ich AI/ML und Deep Data, Data Driven Model anders. Momentan ist das sicher ein Hype Thema. Und für Leute die Pratchett, Clarke nicht gelesen haben ist das magische Technik. Und vermutlich habe ich in frühester Jugend zu viel Asimov, Lem und Co gelesen. Ich sehe nicht das Wegbrechen kompletter kreativer und technischer Berufsbilder. Die Stem Extraktion ist ja ganz nett. Aber die AI Kompositionen sind doch ein wenig blutleer. Aber irgendwann ist ein Michael Jackson, Robbie Williams durchremixt. Und ich persönlich stelle mir das als akustische Hölle vor, 24/7 mit den heissesten Remix Variationen zugedröhnt zu werden. Vielleicht noch moderiert mit einer Stimmenmischung Gottschalk/Koschwitz. Und 3 D Audio und immersive Audio ist auch super, so lange menschliche Kreativität den Raum füllt. *Die moralischen, ethischen und rechtlichen Aspekte lasse ich bewusst aussen vor. (siehe Asimovs 3 Gesetze der Robotik, Clarke’s AI Prediction)
–
Was ich sehe ist das KI und ML Assistenzaufgaben übernehmen werden. Für Routine Aufgaben und auch komplexere Aufgabenstellungen. Das eine KI/AI irgendwann eigenständig N/NP-Probleme löst halte ich für gewagt.
@TobyB Noch so ein Asimov/Lem Fan. 😂 Lese mich als Spätzünder gerade durch die Foundation-Saga durch. Lem ist abgefahren und irgendwie brainfucked, war später als Hörspiel hilfreich, wenn du von irgendeiner Afterhour das überdrehte Hirn in den Schlaf zu prügeln musstest. So viel Input und du schaltest einfach ab, schnell und zuverlässig. Stichwort: Der futurologische Kongress. Nach Asimov kommen Boris und Arkadi Strugatzki. Der Stalker wartet……
Zu KI, William Gibson nicht vergessen, die Derms und Mods hätte ich auch gerne mal probiert. Im realen Leben, KI nein danke! ABBA wird ja keiner gefragt.
Strugatzkis und Gibson sind auch gesetzt. Foundation ist natürlich „umfangreich“ Da hast gut zu tun. Ich spoiler auch nicht ;-) Zur KI, man wird sehen wie es weitergeht. Den unregulierten feuchten Traum, wird es so nicht mehr lange geben. Die Argumentation „Pferdekutscher fanden Autos auch schlecht“ zieht hier nicht. Da generative AI und ML ja nun datengetrieben sind. Das Thema ist spannend. Man sollte das allerdings ohne Hype und Angstmacherei diskutieren. Momentan sehe ich das eher so, nehme ich Leuten ihr Smartphone weg und stell den einen Rechner hin. Scheitert die Hälfte schon an einem sverweis() über zwei Arbeitsblätter mit Variablen in Excel. Ich glaube nicht das es zielführend ist, auf diesen Teil der Menschheit eine KI loszulassen. Ok auf den anderen Teil auch nicht.
@TobyB Als Mensch habe ich menschliche Bedürfnisse. Es gibt für mich nichts schöneres als bahngebrochene Fantasie, die der Verstand versucht in Einklang zu bringen. Oder das berühmte Zitat bei dem ich immer wieder weinen muss: „I’ve seen things you people wouldn’t believe. Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhauser Gate. All those moments will be lost in time like tears in rain. Time to die.“ Gibt es was schöneres als diese Poesie in Bild und Ton? Könnte eine KI so eine Szene authentisch erschaffen? Wenn ich mein Bewußtsein eines Tages konservieren und in Interaktion mit anderen treten könnte, das würde ich machen, wäre dann auch keine reine KI. Gibt es überhaupt „reine“ KI oder sind wir nicht schon mit drin? Wir wissen doch, Magie ist nur hochentwickelte Technik. 😉
Wie sagte Poly Verisof: „Ein bisschen Magie muss sein. Das ist Show und öffnet den Geist für die eigentliche Botschaft.“ Ich glaube nicht da KI eine solche ikonische Szene wie in Bladerunner erschaffen kann. Dazu fehlt ihr Emphatie. Sie kann schlicht und ergreifend nicht den Ausdruck und die Betonung von Scott, Hauer, Ford und Vangelis umsetzen. Was die Transferierung deines Geistes in eine Maschine betrifft, sehe ich schwarz. Die Datenspende wäre immer unvollständig. Menschliche Bedürfnisse lassen sich schlecht in Daten erfassen.
@TobyB Hi Toby, „Stimmenmischung Gottschalk/Koschwitz“ – darauf habe ich gewartet ;) Die Stemextraktion hat bei der Audiorestaurierung sicher Vorteile. Mir ständig neuen Remixen möchte ich auch nicht zugeballert werden. Ansonsten wird das die Herausforderung für die Zukunft sein: eine Balance finden zwischen sinnvoller KI-Assistenz und Kreativität bei der Musikproduktion. Ein Hans Zimmer wird durch KI bestimmt nicht arbeitslos werden. Ich kenne aber einige, die mit Synthesizern oder Software hier und da mal etwas Musik für TV-Produktionen gemacht haben. Dass man solche Zweckmusiken bald mit KI produziert, halte ich schon für sehr wahrscheinlich. Auch der Markt für Übersetzer und Sprecher steht vor einem großen Umbruch.
@costello Ich stell mal das Phrasensparschwein in den Raum und spende 5€. Ich begreife KI als „feuchten Traum“ von Menschen die Kreativität und Wissensarbeit ausschließlich unter Kosten und Betriebswirtschaftlichen Gesichtspunkten abhandeln. Ich halte nichts von disruptiven Geschäftsmodellen. Am Ende des Tages ergibt das Sozialdarwinismus neolibertärer Diktion. Was machen die Kollegen wenn das Rechenzentrum nicht erreichbar ist?
–
Wer trägt dann bitte schön die Folgen einer falschen KI Übersetzung, wer überprüft das? Was ist mit Leuten die Sprache A nach B mittels KI übersetzen lassen. Aber Sprache A gar nicht und Sprache B soeben muttersprachlich beherrschen. Erschleicht der sich nun einen Vorteil? Täuscht er Fähigkeiten vor?
–
Also die derzeitigen Sprachmodelle zur Erzeugung gesprochenen Wortes lassen noch arg zu wünschen übrig. Das wird auch noch eine Weile so bleiben. Ich möchte weder Nachrichten, noch Reportagen oder sonst was von einer KI vorgelesen bekommen. Man kann lange über das für und wider diskutieren. Ich sehe hier im Einsatz von KI und der entsprechenden Infrastruktur keine ökonomischen Vorteile. Ich verschiebe nur mein Budget von den Personal zu den Sachkosten.
–
Assistenzsysteme machen Sinn, aber alles darüber hinaus ist disruptiv.
@TobyB „Was ist mit Leuten die Sprache A nach B mittels KI übersetzen lassen.“
Dafür benutzt man doch schon seit langem ein Übersetzungsprogramm wie Google Translate, und die Dinger sind AUCH nicht perfekt. Mir ist nicht bekannt, daß deswegen mal ein Flugzeug abgestürzt wäre oder sowas…
@mort76 , Sprache mittels KI übersetzen und Flugzeuge mittels Autopilot fliegen lassen, sind nun Äpfel und Birnen. Im privaten Kontext kannst du mit KI fast alles machen aber eben nur fast. Im beruflichen Umfeld sieht das schon wieder anders aus. Das wird sich auch nicht so schnell ändern. Siehe untenstehenden Kommentar.
@costello Ich hab mal unsere Arbeitsrechtexpexten befragt, wie der Sachstand hier ist. Es gilt im deutschen Arbeitsrecht der Grundsatz „Mensch vor Maschine“. Der Einsatz von Übersetzungssoftware und KI zur Spracherzeugung ist Mitbestimmungspflichtig. Desweiteren ist die DSGVO und das AGG zu beachten. Die ganze Thematik ist recht gut und gerichtsfest dokumentiert. Die Mitbestimmungspflicht gilt auch für Bereiche in den Personalräte, also Körperschaften des ÖR und Interessenvertretungen für freie Mitarbeiter wirken. Um das praktisch zu beleuchten, man kann einen AN der kein englisch spricht, nicht dazu zwingen deepl einzusetzen. Sollte der AG dies per Direktionsrecht anordnen, trägt der AG und seine Bevollmächtigten das alleinige Risiko für fehlerhafte Übersetzungen und deren Folgen. Das AGG greift dann, wenn Kollegen die eigentlich keine Sachkunde in englisch haben, sich durch die Benutzung von zB deepl einen Vorteil verschaffen. Das ergooglen eines AI Tools zum Übersetzen von Sprache stellt eine Minderleistung dar. Und kann zu Abmahnungen führen. Ich hab die Benutzung solcher Tools in meinem Team verboten, die Leute sollen keine Bomben bauen, sondern gucken das die Medizin bitte pünktlich und am Stück ankommt. Ob nun in Deutschland oder Rest der Welt.
Ihr solltet euch nicht für zu schlau halten und euch hüten, daß ihr euch mit diesem KI-Scheiß nicht euer eigenes Grab schaufelt.
Irgendwann kickt die KI euch raus und macht euch als Musiker überflüssig — als Menschen sowieso.
Die Menschheit hat in der Vergangenheit leider mehr als einmal unter Beweis gestellt, daß sie nicht in der Lage ist, mit dem, was ihr gegeben wird, verantwortungsvoll umzugehen — angefangen beim Planeten, auf dem wir hier durch’s All düsen bis hin zu Internet, Smartphone und Nukleartechnologie. Egal was, es ist immer dergestalt mißbraucht worden, daß uns am Ende zum Schaden gereicht, was uns eigentlich hätte nutzen sollen.
Aber was weiß ich schon.
Genau so sieht’s aus. 👍👍👍
@iggy_pop Das sehe ich genauso.
Seit 1991 gibt es den Film dazu »Terminator 2 – Tag der Abrechnung«.
Plot: In der Zukunft herrscht Krieg zwischen dem menschlichen Widerstand und der künstlichen Intelligenz Skynet, welche eine Armee von Maschinen befehligt.
Vielleicht erleben wir das noch.
@Franz Walsch Zitat:
„Daniel: Tatsache ist, die künstliche Intelligenz in der Musikproduktion wird ganz viele Leute treffen. Also viel arbeitendes Volk, sag ich mal. Dazu zählen Sprecher, dazu zählen Musikkomponisten, weil der gesamte Bereich Funktionsmusik entfallen wird. Also alles, was da an Komponisten unterwegs ist, wird wegfallen.“
Ist sich dieser Schlauberger eigentlich darüber im klaren, welches unglaubliche soziale Elend da auf uns zukommt, in allen möglichen Bereichen, nicht nur in der Musikproduktion (die — sieht man von denjenigen ab, die dort ihr Brot verdienen — am Ende bloß ein Konsumprodukt herstellt, das der Convenience und dem Lifestyle dient. Alle Musik ist auf ihre Weise „Funktionsmusik“ — was für ein unerträglicher, unreflektierter Dummschwätzer)?
Ich glaube, dieser Daniel weiß gar nicht um die Bedeutung des Wortes „Arbeit“, und er ist noch nie in seinem Leben abends vor Erschöpfung heulend ins Bett gefallen und hat sich fragen müssen, wie er den nächsten Tag — geschweige denn: den Rest vom Leben — schaffen soll.
Ich wünsche ihm und seinem Spießgesellen den Tag, den sie verdienen. Und das böseste Erwachen, das möglich ist: Die Realität.
Von Costello hätte ich bessere Beiträge erwartet, aber andererseits: Mein Blutdruck ist auf 180, und das ganz ohne die vierte Tasse Kaffee. Um mit Kinski zu sprechen (Deutschlandhalle Berlin, 1970): Ich habe jetzt das dringende Bedürfnis, eine Peitsche zu nehmen und sie in eine Fresse zu hauen. In irgendeine.
Daniel spricht aus, was gerade passiert. Und zwar ganz ohne Zynismus und Süffisanz. Seine Prognose ist, dass der Zug inzwischen dermaßen Fahrt aufgenommen haben, dass er nicht mehr zu stoppen ist. Ich habe ein bisschen Einblick, was sich bei den großen Rundfunkanstalten gerade tut. Und kann bestätigen, dass KI da ein Riesenthema ist und auch große Veränderungen für manche Berufsgruppen (zum Beispiel Übersetzer) mit sich bringt. Das muss man nicht gut finden, aber jemanden der das klar benennt, als Dummschwätzer abzuqualifizieren, finde ich daneben. Es ist auch lustig, dass Du jemanden der ein riesiges Gebäude komplett allein durchsaniert hat (also mit seinen eigenen Händen) nachsagt, er wüsste nicht was Arbeit ist. Ich denke einfach, dass Dich das Thema sehr bewegt. Das wiederum verstehe ich sehr gut.
@costello Lieber Costello: Ich muß Dich hoffentlich nicht darüber aufklären, dass es einen gewissen, kleinen Unterschied macht, ob man Arbeit verrichtet um seiner selbst und der eigenen Selbstverwirklichung willen oder ob man als Alleinerziehende(r) mit Minijob und Bürgergeld seine Existenz (und die der einem Anvertrauten) fristen darf, immer mit der Aussicht, überflüssig gemacht zu werden („to be made redundant“ ist so ein wunderschöner Euphemismus).
Wenn man sich den Erwerb einer Immobilie leisten kann, ebenso die Mittel, die zur kompletten Durchsanierung mit eigenen Händen nötig sind, und all seine Zeit in dieses Projekt stecken kann, weil man anscheinend in der Lage ist, aus dem Vollen schöpfen zu können ohne die Notwendigkeit, erstmal Brot auf den Tisch bringen zu müssen, ist das doch eine ganz andere Nummer, als am Existenzminimum herumkrebsen zu müssen.
Das ist ein Privileg, für das man seinem Gott oder wem auch immer eine Kerze anzünden und in tiefster Demut verharren sollte.
„Ich denke einfach, dass Dich das Thema sehr bewegt. Das wiederum verstehe ich sehr gut.“
Stimmt, ich bin ja auch keine KI.
KI ist ja nicht nur in der Musik oder bei den Übersetzern ein Thema. Alle Berufe sind betroffen, sogar die städtische Buchhaltung, wobei es dort wahrscheinlich am längsten dauert bis darauf umgestellt wurde. 😂 Ne mal ernst! Es gibt seit langem Untersuchungen, daß es bald keine ausreichende Anzahl an Jobs mehr geben wird, aufgrund zahlreicher automatisierter Prozesse. Deswegen ja auch der Ansatz mit dem bedingungslosen Grundeinkommen. Ob es wegen KI ist oder weil wir plötzlich lieber selbst mit Sauerteig experimentieren (städtische Angestellte haben dafür Zeit) und deswegen der Bäcker kein Brot mehr verkauft, egal! Bei mir am MRT-Scanner kann das Gerät Untersuchungen seit langem selbst einstellen, ich mache das aber per Hand. Siemens hat die Geräte immer online und kann super das Verhalten von gelernten Assistenten aufzeichnen und in ihre wasauchimmer einpflegen. Eine KI verkürzt bald auch die Scanzeiten, wobei „KI“ mittlerweile für jeden mathematischen Kniff verwendet wird, es vermarktet sich halt gut in den Chefetagen. Auch Ärzte müssen um ihren Job fürchten, weil so ein Chat mit GPT bald besser zuhört, nichts kostet und besser Diagnosen stellt als der neue Assistenzarzt aus Malaysia, den man am Telefon fast nicht versteht, während er einen Katheter legt und der Patient dabei fast verblutet (real!). Und so geht es überall….
„Irgendwann kickt die KI euch raus und macht euch als Musiker überflüssig — als Menschen sowieso.“
Man lebt doch heute schon eher von den Konzerten, und da ist KI ja wohl nicht so gut…
Hatte grad ein Gespräch über „In the air tonight“ & was so ein Studio gekostet hat & was heute mit’m iPad alles möglich ist. Dann hab ich gestern ein Zitat v. Butch Vig über den „gigantischen Ozean der Mittelmäßigkeit“ gelesen. Bin Jahrgang 73 & fand vieles aus den 70ern und 80ern gehaltvoll. Irgendwann Ende der 80er fing es aus meiner Sicht an, dass Technik nicht mehr künstlerisch eingesetzt wurde, sondern Können vermissen ließ. Das ging mit Talkshows, Daily Soaps im Fernsehen weiter & irgendwann sangen Soap Stars Songs nach, die nicht annähernd ans Original heranreichten, a. den Leuten gefiel es. Wenn ich heute Mainstream-Radio höre, dann ist vieles nett; tut nicht weh. Das reicht für viele aus! Damit komme ich zur Technik. Wenn ich ein Chord-Tool benutze oder ein EZ-Keys, dann benötige ich am Ende zumindest immer noch Geschmack, um mich für eine Akkordfolge zu entscheiden. Ich bin aktuell klamm & benötige eine Sängerin. Kostet mich pro Song 500-1000 €. Sehe nun ein Programm für 99 €. Ich muss die Noten & Text einspielen & fertig. Verlockend, a. wenn ich(!) einen Menschen wg. Kohle gg. ein Tool austausche, werden Labels das auch machen! Damit würde ich mich & meine Daseinsberechtigung letztlich auch selbst verneinen! Es ist das Spiel mit dem Feuer! Den meisten Hörern wird KI-Musik reichen. Also wird es kommen = billiger! Das Spiel mit d. Feuer hat der Mensch immer verloren!
Jede KI wird millionenfach von Menschen trainiert, welche in diesem Fall der gehörten Musik emotionale Attribute zuordnen müssen. Da Musik subjektiv empfunden wird, gibt es kein eindeutiges Ergebnis. Daher muss der nutzende Mensch final entscheiden was passt. Daher ist eine KI ein toller Assistent, mehr aber auch nicht. Diese autonom entscheiden zu lassen wäre grob fahrlässig.
@Stratosphere Das sounddub-Tool arbeitet ja mit einer immer weiter verfeinerten Suche. Du erhältst 5 Vorschläge, die Du verwirfst oder als Ausgangspunkt für neue, hoffentlich passendere Ergebnisse nimmst. Die Entscheidung liegt also immer beim Nutzer, der aber deutlich entlastet wird. Bei der Auswahl der richtige Musik für ein Video hatte ich oft das Problem, dass die meisten vorgegebenen Kategorisierungen viel zu grob sind. Da wäre dieses Tool sicher hilfreich gewesen.
Das ganze klingt wie ein Werbeartikel – viel mehr ist da nicht dahinter. Banale Fantasie.
@kinsast Wieso Fantasie? Die Stemextraktion in der praktischen Anwendung findest Du im Video Audiorestaurierung. Amazona hat auch schon mal ein audiotechnisch verunglücktes Interview mit Hans Zimmer mit Izotope gerettet. Das funktioniert sehr gut und wird in professionellen Studios gerne eingesetzt. Die Sortierung nach Emotionen dagegen ist eine sehr spezielle Anwendung und für Rundfunkanstalten, Streamingdienste, Werbeagenturen interessant.
Naja denen die mit dieser Neuen Zukunft ne Menge Schotter verdienen kann es natürlich egal sein welchen Schaden die KI verursacht. Bezahlen werden sowieso andere dafür. Das in kreativen Händen spannende Dinge dabei rauskommen werden keine Frage. Obwohl Ich trotzdem glaube das die Beastie Boys nichts von dieser Technik verwendet hätten. Kann mir schon vorstellen wie in den Chefetagen der Großkonzerne oder in der Industrie gefeiert wird das der unliebsame Faktor Mensch bald in manchen Bereichen verschwunden sein wird.
@zeitweh Hi Zeitweh, ob die Beastie Boys das Tool benutzt hätten, ist wirklich eine spannende Frage. Ich habe mich bei meinem Emax-Artikel mit Paul’s Boutique beschäftigt. Produziert wurden sie ja von den Dust Brothers und die waren mit dem Emax nicht sehr glücklich: „But we’ve never been in love with the degraded sound of those early machines, we were always trying to make samples sound better“ Und ein zweites Zitat: „We had Pro Tools in our heads before it even existed. Since both John and I came from a computer background, we knew what computers were capable of, and we were kind of bombed that the samplers were still so lo-fi or hard to use.“ Von daher könnte mir schon vorstellen, die hätten so ein Tool benutzt, wenn es das damals schon gegeben hätte.
Tolles Interview…!
Wenn ich es richtig verstanden habe, bedeutet es auch, dass man bspw. alte Konzertmitschnitte ( da spricht der TD-Fan) in neuer Qualität aufarbeiten könnte, oder?
Was kostet sowas?
@THo65 Die dann die heutige Jugend auf ihren iPhones und billigen Ohrenstöpsel eventuell anhört! 😂
@JohnDrum das ist so eine argumentation, die ich überhaupt nicht nachvollziehen kann…ich hatte in meiner jugend – trotz wohlsituiertem elternhaus – eine no-name kaufhauskompaktanlage und trotz ihres billigklangs war ich in der lage, mit begeisterung musik zu hören und zu empfinden; erst als ich mit 20 auszog legte ich mir nach und nach hochwertiges hifi equipment zu….
@dilux Nur dass man heute keine Hifi Anlagen mehr kauft!
Ich hatte mich auch in meiner Jugend damit beschäftigt und mir eine schöne Sony zusammengestellt und tolle Musik damit gehört. Habe auch noch viele tolle Prospekte aus den 80er dazu. Gleiche Situation wie bei dir! Aber heute scheint es etwas anders zu laufen!
@JohnDrum Zum Glück gehöre ich nicht der iPhone/Ohrstöpsel-Generation an….
@THo65 Hi Tho65, das wäre durchaus möglich. Über Preise habe ich mit den beiden aber nicht gesprochen.
@costello Daniel und Markus sollten sich mal bei eastgate melden, die 76/77’er Konzerte würde ich mir glatt zulegen…..😄…..!!
Werbung, Jingles, dolby atmos ™ …sind nicht meine Welt.
Auf grauenhafte dolby atmos remixe von Elvis, Billie Holiday, ect. verzichte ich auch sehr gerne.
Ob das tagging system für den RTL Redakteur funktioniert ist mir auch total egal.
🤷🏻♂️
hier werden hochtrabende begriffe umeinander geworfen und es wird wenig gesagt.
Zitat: „hier werden hochtrabende begriffe umeinander geworfen und es wird wenig gesagt.“
Sind bestimmt Experten.
Die uns alle mit ihrer Sachkenntnis in den Untergang reiten werden.
ach, ich hab da wenig angst.
Hauptsache hochtrabend von künstlicher Intelligenz gelabert ;) im Endeffekt ist das nur Mustervergleich mit was auch immer die engine angelernt wurde.
Das ist doch jetzt die Chance um mit sich mit seiner Musik von den bekannten Mustern abzusetzen.
Die Stimmspielereien mögen ja für Werbung toll sein, wenn einem Steve Jobs Kloreiniger verkaufen will und so,
aber kein mensch will das David Bowie Imitat aus dem Rechner hören. Warum sollte man sich das anhören wollen???
Nun wenn wir so betrachten, was heute so als KI bezeichnet wird ist es im Grunde immer,
Deklaratives Wissen, oder auch „knowing what“, bezeichnet das Sachwissen, also das Wissen über Sachverhalte, wie zum Beispiel Fakten und Begriffe. Der Erwerb findet durch Vermittlung statt.
Die Vermittlung ist das Training der KI.
Somit ist die KI eine Sammlung von Wissen, die sich weiterentwickelt durch neue Sammlung von Wissen. Ist dies jetzt das Ende unserer Arbeitswelt? Eher nicht, denn es wird langsam klar, AI wird die Arbeitswelt verändern, Routinen abnehmen, aber nicht etwas Neues schaffen.
Das gefährliche ist, die Erstellung von Inhalten aus den (statistischen) Datenpunkten, die dann kaum als künstlich zu erkennen sind. Ob es Nachrichten, Texte, Bilder oder Musik ist. Ein Wahrheitsgehalt der Information ist auch nicht per se nicht gegeben. Weiterhin das Schwinden unserer Fähigkeiten, weil wir müssen das nicht lernen, weil wir ja KI nutzen. Vom Smombie (Smartphone Zombie) zur totalen Technologie Abhängigkeit ist kein weiter Weg.
Mich wundert die „Verliebtheit“ der Musikindustrie in KI kaum, denn es ist nur die konsequente Fortsetzung des CoypCat Phänomens. Es wird auf der Suche nach dem finanziellen Erfolg, dem Profit, so alles, was geht „reused“. Im Grunde macht man schon seit geraumer Zeit das, was eine KI auch kann. So ist der Einsatz der KI, logisch?
/1
@TomH Zu wenig Zeichen 😅
Nur ohne neue Information, trocknet die KI aus. KI nur trainiert mit KI-Inhalten geht nicht. Haben wir nicht fast diese Situation in der Musik Industrie? Viel klingt wie schon einmal gehört, manches ist es ganz offensichtlich. Wirkliche Kreativität? Eher Fehlanzeige, dafür die Jagd nach dem vertrauten, nach den erfolgreichen Konzepten und Sequenzen, nach dem „Vintage“ Sound, dem ach so vertrauten für den Profit.
Somit erwarte ich eher das die KI den aktuellen Trend des kopieren noch verstärkt, wahrscheinlich auf subtilere Art und Weise. So wird der Punkt der absoluten Langweile noch etwas rausgeschoben.
Wer mag kann sich mal diesen Beitrag von Marcus
( https://de.m.wikipedia.org/wiki/Marcus_Hutchins ) ansehen.
Es ist die KI betrachtet aus dem Blickwinkel eines IT – Malwareforscher, aber vieles ist übertragbar.
https://youtu.be/Vj157J3N2eI
Wir haben heute KI und nicht AGI. „An artificial general intelligence (AGI) is a type of hypothetical intelligent agent“. Eine KI die neues schafft, ist nur hypothetisch und noch nicht Realität.
Ich gehe mit Marcus konform, Meldungen über AGI muss man 3 mal prüfen, denn Geld einsammeln ist gerne mal kreativ.
The End Of Music. Nur noch Produkt.
Dieselbe Art von dummem Effizienz-Geschwafel wie in Finanzkreisen.
I wanna puke… Schöne Neue Welt. Es geht immer noch dümmer…
Warum geht unser Planet den Bach runter???
Zitat: „Es geht immer noch dümmer…“
Ein Grund mehr, auf KI zu bauen.
Gerade für die Dummen, und wie wir dank Urban Priol wissen, ist die Mutter der Dummen immer schwanger.
Zitat: „Warum geht unser Planet den Bach runter???“
„Human beings are a disease, the cancer of this planet, you’re like the plague.“ (Agent Smith — Matrix)
„…und wie wir dank Urban Priol wissen, ist die Mutter der Dummen immer schwanger…“
Zu gut für Urban Priol dachte ich gerade ;-) Also mal gegoogelt.
Original wohl: „Die Mutter der Dummheit ist immer schwanger.“ -> afghanische Weisheit (https://www.science-at-home.de/wiki/index.php/Sprichw%C3%B6rter_anderer_L%C3%A4nder)
KI ist mit Abstand das dümmste Projekt seit dem Turmbau zu Babel.
Immerhin hat der Turmbau noch ansehnliche Spuren in der bildenden Kunst hinterlassen. Und ein (nicht so pralles) Album von Klaus Schulze.
@Gero van Apen: Danke für die Info, wieder was dazugelernt. Hat sich heute Morgen schon wieder das Aufstehen gelohnt.
Größenwahn kommt vor dem Fall.
Und Zappa formulierte mal sinngemäß. dass nicht Wasserstoff, sondern Dummheit das am weitesten im Universum verbreitete Element darstellt. Dem ist nichts hinzuzufügen.
„Zwei Dinge sind unendlich: Die Dummheit und das All. Wobei ich mir beim All noch nicht einmal sicher bin.“ (Albert Einstein, später adaptiert von Blixa Bargeld)
Zappa war auch ein Guter.
Danke für den interessanten Artikel!
Respekt an die beiden Herren, was selbige da aufgebaut haben fällt nicht reif vom Stamm.
@The End Of Music. Nur noch Produkt.
Dem folgend auf Spotify hochgeladen.
So ein Thema muss man sacken lassen. Erstmal muss ich zu meiner Schande gestehen, daß ich diese Voice-Generatoren auch selbst mal genutzt habe, weil damals mein Mikro kaputt war. Habe dann Plato in „Australian Male“ vorlesen lassen und in Ableton aufbereitet. In Hollywood wird aktuell wegen KI gestreikt und wenn ich das Interview hier richtig lese, dann können Künstler demnächst höchstens noch ihr Timbre lizenzieren lassen, den Rest macht eine KI. Letztlich kommt es darauf an was wir daraus machen. Fest steht nur daß die Möglichkeiten mehr werden. Ob deswegen der Doomsday kommt, aber….. kommt der nicht sowieso? 😉
> […] Letztlich kommt es darauf an was wir daraus machen. […]
Zum Teufel damit, was sonst? 😈
Hallo zusammen.
Wir alle sind auch Konsumenten, wir müssen das KI-„Zeugs“ nicht konsumieren oder nutzen.
Wir müssen auch nicht im „Metaversum“ abhängen oder Konzerte von Avataren besuchen.
Wir müssen unsere Musik/“Werke“ auch nicht auf Spotify und Co. veröffentlichen.
Wir könnten auch nur noch live auftreten, den Computer zumindest auf der Bühne verbannen.
Raus in den Park, in die Stadt, spontan Konzerte geben, echte handgemachte Musik.
Wir könnten unsere Musik/“Werke“ dann auch explizit als „KI-frei“ deklarieren.
Ich hoffe es wird Radiosender geben, die genau solche Musik/Musiker*innen unterstützen wollen, die müssen wir finden.
Warum gibt es Show Cooking? Der Konsument soll sehen, da arbeitet ein Mensch, mit ehrlichen Produkten.
Ein Mensch, der auch noch kochen kann und nicht nur einfach Convenience-Produkte zusammenschmeißt.
„Gute“ Bäckereien haben das längst erkannt und zeigen, wie „echtes“ Brot gemacht wird, ebenso Landwirte.
Wir sollten es m.M.n. genauso machen, zugleich versuchen, jedweder KI-Plattform/Firma, die „Verwurstung“ unseres geistigen Eigentumes untersagen.
Ich hoffe, dass bald alles mittels KI produzierte, künftig via Siegel/Wasserzeichen o.ä., erkennbar sein wird.
Wenn das gelänge, wäre m.M.n. schon viel geschafft.
Gruß
SlapBummPop
Sehr spannendes Interview und noch spannendere Diskussion hier unter uns. Ich selbst habe keinerlei Angst vor der KI, denn es ist auch ein Tool das von Menschen gemacht und genutzt wird. Natürlich kenne ich als Lem-Fan viele Möglichkeiten was alles durch Technik schief gehen kann, aber wir sollten uns auch die vielen Vorteile die wir haben ansehen.
Seit ich die Schule verlassen habe – lange her, es geht keine 10 Jahre mehr bis zur Pension – arbeite ich in der Textilindustrie. In diesen über 40 Jahren habe ich die älteste Technologie die die Menschheit entwickelt hat, gesehen zusammen zu brechen, sich komplett zu verändern und Produkte auf den Markt zu werfen die nicht gebraucht werden (ca. 50% der heute produzierten Kleider werden nie getragen, sondern landen unbenutzt auf dem Müll). Nahezu alle Kleider werden ohne dass sie kaputt sind entsorgt, da sie extrem billig sind werden die gekauft wie blöd und es interessiert auch kaum jemanden, dass die meisten von Menschen produziert werden, die wie Sklaven behandelt werden.
Etwas weit hergeholt, aber ich sehe da viele Prallelen in der Musik. Massenweise Müll der kaum gehört wurde, ständige Wiederholungen, alles hört sich technisch gut an, ist aber bevor das Stück fertig ist schon so langweilig, dass vieles weggeskipt wird und das nächste langweilige Stück gestartet wird.
@liquid orange Und doch gibt es im Textilen wie im Musikalischen einige „Gallier“ die ihren eigenen Weg gehen und das machen was für sie gut ist. Handarbeit, sei es etwas selbst zu nähen oder selbst zu spielen ist unersetzbar. Darauf müssen wir bauen.
Und die Technik die entwickelt wird, macht alles noch spannender. So ist auch mein Job in einer extrem schwierigen Industrie massiv spannender geworden, da wir mit Technik ganz andere Sachen machen können die bisher nicht möglich waren. Kleider interessieren mich kaum mehr, technische Textilien sind die faszinierende Spielwiese. Und genau so soll es in der Musik sein, nutzt was möglich ist und zusammen mit Eurer Kreativität kann gigantisches entstehen!
Ich finde den Ansatz des sounddub Systems interessant Musik nach den drei Hauptparametern Flow, Emotion und Energy abzufragen zu können. Soweit ich es verstanden habe bewegt sich Flow dabei zwischen langsam und schnell, Emotion zwischen dunkel und hell und Energy zwischen niedrig und hoch. User stehen jetzt allerdings vor dem Problem eine menschliche Emotion wie Wut oder Freude auf diese 3 Parameter abzubilden. Ich halte deshalb die Namensgebung des Parameters Emotion für nicht gut, besser wäre der Begriff „Mood (Stimmung)“. Musik die Wut untersteicht könnte dann mit Flow-schnell, Stimmung-dunkel und Energy-hoch gefunden werden, Freude z.B. mit Flow-mittel, Stimmung-hell und Energy-hoch. Es wurde ja schon angesprochen, dass die Interpretation einer Musik, z.B. als freudig, kulturell beeinflusst ist, das System das aber berücksichtigt. Zusätzlich sehe ich, dass Emotionen nicht eindeutig auf die 3 Parameter abgebildet werden können, die Emotion Verachtung z.B. könnte man mit Flow-mittel bis schnell, Stimmung-dunkel und Energy-niedrig bis mittel oder eben auch anders abbilden. Mich würden Praxiserfahrungen von sounddub Benutzern interessieren.
Künstliche Intelligenz im Musikbereich wird glaube ich sehr schwer wer hat die rechte an den Songtexten dann und so weiter. Ich denke das wird noch einige zeit (hoffentlich) dauern
Kein halbes Jahr später haut AKAI Stem-Separation für die MPCs für nahezu lau heraus. Noch fehlerbehaftet und nicht so filigran. Aber B2C für diese „Technik“ ist nun wirklich ein alter Hut. SpectraLayers ist nun ja auch schon seit Jahren am Markt. Das ist nicht vor der Welle… sondern Jahre nach dem Tsunami.
Es gibt genug Sender und Firmen, die Compliance-Policies einfordern, dass keine AI Tools eigesetzt wurden. Sofern „AI-Kreativität“ Standard werden sollte, sind wir noch viele Jahre oder Dekaden davon entfernt.
AI setzt immer die Datenbasis Vergangenheit voraus. Solange die technischen Ressourcen noch nicht vorhanden sind (unendlicher Speicherplatz und v.a. unendlich Strom) wird das immer fehlerbehaftet sein, wenn man versucht etwas „neues“ zu kreieren.
Und wenn die Gelder und Fördermittel ausgehen, wird wieder eine neue GenX Variante eines AI Modells als Sau durchs Dorf getrieben. Oder alle Sendeanstalten werden mit Pressemitteilungen versehen, dass AI die Menschheit auslöschen könnte.
Heute (16.02.24) haut OpenAi die Meldung über die neue Video-Engine Sora raus… Und die ist?: Nach Unbrauchbar und visuell langweilig für das Auge.
Aber die Sau AI rennt halt richtig gut durchs Dorf…
P.S.: Sollte dieses Interview (wir reden hier von Funktionen, die mind. 5 Jahre alt sind und nix mit AI zu tun haben) wirklich ernst gemeint sein – eine Website ohne SSL Zertifikat ist nicht mal die unterste Schublade von Professionalität…
Gibt es in dem Artikel überhaupt kritische Einwände für den Einsatz von KI und dem hier beschriebenen Anwendungsfeld? Es handelt sich hierbei um ein striktes B2B Modell!